
Technology
Open source LLMs hit Europe’s digital sovereignty roadmap

Large language models (LLMs) landed on Europe’s digital sovereignty agenda with a bang last week, as news emerged of a new program to develop a series of “truly” open source LLMs covering all European Union languages.
This includes the current 24 official EU languages, as well as languages for countries currently negotiating for entry to the EU market, such as Albania. Future-proofing is the name of the game.
OpenEuroLLM is a collaboration between some 20 organizations, co-led by Jan Hajič, a computational linguist from the Charles University in Prague, and Peter Sarlin, CEO and co-founder of Finnish AI lab Silo AI, which AMD acquired last year for $665 million.
The project fits a broader narrative that has seen Europe push digital sovereignty as a priority, enabling it to bring mission-critical infrastructure and tools closer to home. Most of the cloud giants are investing in local infrastructure to ensure EU data stays local, while AI darling OpenAI recently unveiled a new offering that allows customers to process and store data in Europe.
Elsewhere, the EU recently signed an $11 billion deal to create a sovereign satellite constellation to rival Elon Musk’s Starlink.
So OpenEuroLLM is certainly on-brand.
However, the stated budget just for building the models themselves is €37.4 million, with roughly €20 million coming from the EU’s Digital Europe Programme — a drop in the ocean compared to what the giants of the corporate AI world are investing. The actual budget is more when you factor in funding allocated for tangential and related work, and arguably the biggest expense is compute. The OpenEuroLLM project’s partners include EuroHPC supercomputer centers in Spain, Italy, Finland, and the Netherlands — and the broader EuroHPC project has a budget of around €7 billion.
But the sheer number of disparate participating parties, spanning academia, research, and corporations, have led many to question whether its goals are achievable. Anastasia Stasenko, co-founder of LLM company Pleias, questioned whether a “sprawling consortia of 20+ organizations” could have the same measured focus of a homegrown private AI firm.
“Europe’s recent successes in AI shine through small focused teams like Mistral AI and LightOn — companies that truly own what they’re building,” Stasenko wrote. “They carry immediate responsibility for their choices, whether in finances, market positioning, or reputation.”
Up to scratch
The OpenEuroLLM project is either starting from scratch or it has a head start — depending on how you look at it.
Since 2022, Hajič has also been coordinating the High Performance Language Technologies (HPLT) project, which has set out to develop free and reusable datasets, models, and workflows using high-performance computing (HPC). That project is scheduled to end in late 2025, but it can be viewed as a sort of “predecessor” to OpenEuroLLM, according to Hajič, given that most of the partners on HPLT (aside from the U.K. partners) are participating here, too.
“This [OpenEuroLLM] is really just a broader participation, but more focused on generative LLMs,” Hajič said. “So it’s not starting from zero in terms of data, expertise, tools, and compute experience. We have assembled people who know what they’re doing — we should be able to get up to speed quickly.”
Hajič said that he expects the first version(s) to be released by mid-2026, with the final iteration(s) arriving by the project’s conclusion in 2028. But those goals might still seem lofty when you consider that there isn’t much to poke at yet beyond a bare-bones GitHub profile.
“In that respect, we are starting from scratch — the project started on Saturday [February 1],” Hajič said. “But we have been preparing the project for a year [the tender process opened in February 2024].”
From academia and research, organizations spanning Czechia, the Netherlands, Germany, Sweden, Finland, and Norway are part of the OpenEuroLLM cohort, in addition to the EuroHPC centers. From the corporate world, Finland’s AMD-owned AI lab Silo AI is on board, as are Aleph Alpha (Germany), Ellamind (Germany), Prompsit Language Engineering (Spain), and LightOn (France).
One notable omission from the list is that of French AI unicorn Mistral, which has positioned itself as an open source alternative to incumbents such as OpenAI. While nobody from Mistral responded to TechCrunch for comment, Hajič did confirm that he tried to initiate conversations with the startup, but to no avail.
“I tried to approach them, but it hasn’t resulted in a focused discussion about their participation,” Hajič said.
The project could still gather new participants as part of the EU program that’s providing funding, though it will be limited to EU organizations. This means that entities from the U.K. and Switzerland won’t be able to take part. This flies in contrast to the Horizon R&D program, which the U.K. rejoined in 2023 after a prolonged Brexit stalemate and which provided funding to HPLT.
Build up
The project’s top-line goal, as per its tagline, is to create: “A series of foundation models for transparent AI in Europe.” Additionally, these models should preserve the “linguistic and cultural diversity” of all EU languages — current and future.
What this translates to in terms of deliverables is still being ironed out, but it will likely mean a core multilingual LLM designed for general-purpose tasks where accuracy is paramount. And then also smaller “quantized” versions, perhaps for edge applications where efficiency and speed are more important.
“This is something we still have to make a detailed plan about,” Hajič said. “We want to have it as small but as high-quality as possible. We don’t want to release something which is half-baked, because from the European point-of-view this is high-stakes, with lots of money coming from the European Commission — public money.”
While the goal is to make the model as proficient as possible in all languages, attaining equality across the board could also be challenging.
“That is the goal, but how successful we can be with languages with scarce digital resources is the question,” Hajič said. “But that’s also why we want to have true benchmarks for these languages, and not to be swayed toward benchmarks which are perhaps not representative of the languages and the culture behind them.“
In terms of data, this is where a lot of the work from the HPLT project will prove fruitful, with version 2.0 of its dataset released four months ago. This dataset was trained 4.5 petabytes of web crawls and more than 20 billion documents, and Hajič said that they will add additional data from Common Crawl (an open repository of web-crawled data) to the mix.
The open source definition
In traditional software, the perennial struggle between open source and proprietary revolves around the “true” meaning of “open source.” This can be resolved by deferring to the formal “definition” as per the Open Source Initiative, the industry stewards of what are and aren’t legitimate open source licenses.
More recently, the OSI has formed a definition of “open source AI,” though not everyone is happy with the outcome. Open source AI proponents argue that not only models should be freely available, but also the datasets, pretrained models, weights — the full shebang. The OSI’s definition doesn’t make training data mandatory, because it says AI models are often trained on proprietary data or data with redistribution restrictions.
Suffice it to say, the OpenEuroLLM is facing these same quandaries, and despite its intentions to be “truly open,” it will probably have to make some compromises if it’s to fulfill its “quality” obligations.
“The goal is to have everything open. Now, of course, there are some limitations,” Hajič said. “We want to have models of the highest quality possible, and based on the European copyright directive we can use anything we can get our hands on. Some of it cannot be redistributed, but some of it can be stored for future inspection.”
What this means is that the OpenEuroLLM project might have to keep some of the training data under wraps, but be made available to auditors upon request — as required for high-risk AI systems under the terms of the EU AI Act.
“We hope that most of the data [will be open], especially the data coming from the Common Crawl,” Hajič said. “We would like to have it all completely open, but we will see. In any case, we will have to comply with AI regulations.”
Two for one
Another criticism that emerged in the aftermath of OpenEuroLLM’s formal unveiling was that a very similar project launched in Europe just a few short months previous. EuroLLM, which launched its first model in September and a follow-up in December, is co-funded by the EU alongside a consortium of nine partners. These include academic institutions such as the University of Edinburgh and corporations such as Unbabel, which last year won millions of GPU training hours on EU supercomputers.
EuroLLM shares similar goals to its near-namesake: “To build an open source European Large Language Model that supports 24 Official European Languages, and a few other strategically important languages.”
Andre Martins, head of research at Unbabel, took to social media to highlight these similarities, noting that OpenEuroLLM is appropriating a name that already exists. “I hope the different communities collaborate openly, share their expertise, and don’t decide to reinvent the wheel every time a new project gets funded,” Martins wrote.
Hajič called the situation “unfortunate,” adding that he hoped they might be able to cooperate, though he stressed that due to the source of its funding in the EU, OpenEuroLLM is restricted in terms of its collaborations with non-EU entities, including U.K. universities.
Funding gap
The arrival of China’s DeepSeek, and the cost-to-performance ratio it promises, has given some encouragement that AI initiatives might be able to do far more with much less than initially thought. However, over the past few weeks, many have questioned the true costs involved in building DeepSeek.
“With respect to DeepSeek, we actually know very little about what exactly went into building it,” Peter Sarlin, who is technical co-lead on the OpenEuroLLM project, told TechCrunch.
Regardless, Sarlin reckons OpenEuroLLM will have access to sufficient funding, as it’s mostly to cover people. Indeed, a large chunk of the costs of building AI systems is compute, and that should mostly be covered through its partnership with the EuroHPC centers.
“You could say that OpenEuroLLM actually has quite a significant budget,” Sarlin said. “EuroHPC has invested billions in AI and compute infrastructure, and have committed billions more into expanding that in the coming few years.”
It’s also worth noting that the OpenEuroLLM project isn’t building toward a consumer- or enterprise-grade product. It’s purely about the models, and this is why Sarlin reckons the budget it has should be ample.
“The intent here isn’t to build a chatbot or an AI assistant — that would be a product initiative requiring a lot of effort, and that’s what ChatGPT did so well,” Sarlin said. “What we’re contributing is an open source foundation model that functions as the AI infrastructure for companies in Europe to build upon. We know what it takes to build models, it’s not something you need billions for.”
Since 2017, Sarlin has spearheaded AI lab Silo AI, which launched — in partnership with others, including the HPLT project — the family of Poro and Viking open models. These already support a handful of European languages, but the company is now readying the next iteration “Europa” models, which will cover all European languages.
And this ties in with the whole “not starting from scratch” notion espoused by Hajič — there is already a bedrock of expertise and technology in place.
Sovereign state
As critics have noted, OpenEuroLLM does have a lot of moving parts — which Hajič acknowledges, albeit with a positive outlook.
“I’ve been involved in many collaborative projects, and I believe it has its advantages versus a single company,” he said. “Of course they’ve done great things at the likes of OpenAI to Mistral, but I hope that the combination of academic expertise and the companies’ focus could bring something new.”
And in many ways, it’s not about trying to outmaneuver Big Tech or billion-dollar AI startups; the ultimate goal is digital sovereignty: (mostly) open foundation LLMs built by, and for, Europe.
“I hope this won’t be the case, but if, in the end, we are not the number one model, and we have a ‘good’ model, then we will still have a model with all the components based in Europe,” Hajič said. “This will be a positive result.”

Technology
The Case for Custom eLearning Platforms: Why Organizations Are Making the Switch

The corporate eLearning market has exploded in recent years, growing over 800% since 2000. As the demand for eLearning continues to accelerate, more and more organizations are finding that off-the-shelf solutions cannot keep pace with their training needs. This has led many companies to make the switch to custom-built eLearning platforms tailored specifically for their requirements.
There are several key reasons driving the demand for customized eLearning tools:
Greater Flexibility and Scalability
Generic eLearning software packages often impose rigid constraints that limit their ability to adapt to an organization’s evolving needs. Meanwhile, the “one-size-fits-all” approach fails to support the personalized learning critical for employee development. Custom platforms provide flexibility to add and modify features to match ever-changing business goals. As companies scale training across global workforces, custom solutions built on cloud infrastructure can scale seamlessly to handle growing demand.
Deeper Integration Across Systems
Smooth integration with existing HR, LMS, and other business systems is critical for optimizing training workflows. However, off-the-shelf tools rarely integrate well, creating data and process siloes. Custom platforms can tightly integrate role-based learning paths with core business applications, sync user profiles, enable single sign-on, and more. This level of integration catalyzes more impactful training function.
Better Data and Analytics
Generic software severely limits access to data insights that drive improvement. Custom platforms unlock a trove of analytics on content consumption, learner progression, platform adoption, and real-time feedback. Integrated analytics dashboards and APIs allow businesses to derive deep visibility across the learner lifecycle. These insights help continuously enhance learner experience, target development gaps, and demonstrate direct training ROI.
Enhanced Learner Engagement
For modern learners accustomed to consumer-grade digital experiences, poor platform usability quickly erodes engagement. Custom designs allow companies to incorporate familiar features from popular apps and websites while optimizing for their audience. Adaptive learning approaches further personalize content to individual styles and needs. With modular component architecture, custom platforms stay on the cutting edge of new modalities like AR/ VR to captivate learners.
Brand and Culture Alignment
Off-the-shelf tools impose a generic and often disruptive experience that clashes with existing brand identity and culture. In contrast, custom platforms allow organizations to carry over familiar styling, voice, and workflow patterns. Consistency in experience preserves brand recognition while smoother onboarding leads to wider adoption across all employee groups. Over time, the platform can evolve alongside cultural changes as well.
While custom elearning tools require greater upfront investment, for enterprise training needs, the long-term benefits far outweigh the costs. The ability to mold platforms to current and future needs results in greater leverage from learning spend.
As businesses demand ever-more from their learning technology, custom solutions provide the agility needed for true scale. Rather than forcing training functions into the constraints of generic software, custom elearning development keeps the focus on nurturing talent and capabilities. For any organization looking to drive workforce transformation through learning, custom elearning represents the way forward.
Technology
Pintarnya raises $16.7M to power jobs and financial services in Indonesia

Pintarnya, an Indonesian employment platform that goes beyond job matching by offering financial services along with full-time and side-gig opportunities, said it has raised a $16.7 million Series A round.
The funding was led by Square Peg with participation from existing investors Vertex Venture Southeast Asia & India and East Ventures.
Ghirish Pokardas, Nelly Nurmalasari, and Henry Hendrawan founded Pintarnya in 2022 to tackle two of the biggest challenges Indonesians face daily: earning enough and borrowing responsibly.
“Traditionally, mass workers in Indonesia find jobs offline through job fairs or word of mouth, with employers buried in paper applications and candidates rarely hearing back. For borrowing, their options are often limited to family/friend or predatory lenders with harsh collection practices,” Henry Hendrawan, co-founder of Pintarnya, told TechCrunch. “We digitize job matching with AI to make hiring faster and we provide workers with safer, healthier lending options — designed around what they can reasonably afford, rather than pushing them deeper into debt.”
Around 59% of Indonesia’s 150 million workforce is employed in the informal sector, highlighting the difficulties these workers encounter in accessing formal financial services because they lack verifiable income and official employment documentation.
Pintarnya tackles this challenge by partnering with asset-backed lenders to offer secured loans, using collateral such as gold, electronics, or vehicles, Hendrawan added.
Since its seed funding in 2022, the platform currently serves over 10 million job seeker users and 40,000 employers nationwide. Its revenue has increased almost fivefold year-over-year and expects to reach break-even by the end of the year, Hendrawn noted. Pintarnya primarily serves users aged 21 to 40, most of whom have a high school education or a diploma below university level. The startup aims to focus on this underserved segment, given the large population of blue-collar and informal workers in Indonesia.
Techcrunch event
San Francisco
|
October 27-29, 2025
“Through the journey of building employment services, we discovered that our users needed more than just jobs — they needed access to financial services that traditional banks couldn’t provide,” said Hendrawan. “We digitize job matching with AI to make hiring faster and we provide workers with safer, healthier lending options — designed around what they can reasonably afford, rather than pushing them deeper into debt.”

While Indonesia already has job platforms like JobStreet, Kalibrr, and Glints, these primarily cater to white-collar roles, which represent only a small portion of the workforce, according to Hendrawan. Pintarnya’s platform is designed specifically for blue-collar workers, offering tailored experiences such as quick-apply options for walk-in interviews, affordable e-learning on relevant skills, in-app opportunities for supplemental income, and seamless connections to financial services like loans.
The same trend is evident in Indonesia’s fintech sector, which similarly caters to white-collar or upper-middle-class consumers. Conventional credit scoring models for loans, which rely on steady monthly income and bank account activity, often leave blue-collar workers overlooked by existing fintech providers, Hendrawan explained.
When asked about which fintech services are most in demand, Hendrawan mentioned, “Given their employment status, lending is the most in-demand financial service for Pintarnya’s users today. We are planning to ‘graduate’ them to micro-savings and investments down the road through innovative products with our partners.”
The new funding will enable Pintarnya to strengthen its platform technology and broaden its financial service offerings through strategic partnerships. With most Indonesian workers employed in blue-collar and informal sectors, the co-founders see substantial growth opportunities in the local market. Leveraging their extensive experience in managing businesses across Southeast Asia, they are also open to exploring regional expansion when the timing is right.
“Our vision is for Pintarnya to be the everyday companion that empowers Indonesians to not only make ends meet today, but also plan, grow, and upgrade their lives tomorrow … In five years, we see Pintarnya as the go-to super app for Indonesia’s workers, not just for earning income, but as a trusted partner throughout their life journey,” Hendrawan said. “We want to be the first stop when someone is looking for work, a place that helps them upgrade their skills, and a reliable guide as they make financial decisions.”
Technology
OpenAI warns against SPVs and other ‘unauthorized’ investments

In a new blog post, OpenAI warns against “unauthorized opportunities to gain exposure to OpenAI through a variety of means,” including special purpose vehicles, known as SPVs.
“We urge you to be careful if you are contacted by a firm that purports to have access to OpenAI, including through the sale of an SPV interest with exposure to OpenAI equity,” the company writes. The blog post acknowledges that “not every offer of OpenAI equity […] is problematic” but says firms may be “attempting to circumvent our transfer restrictions.”
“If so, the sale will not be recognized and carry no economic value to you,” OpenAI says.
Investors have increasingly used SPVs (which pool money for one-off investments) as a way to buy into hot AI startups, prompting other VCs to criticize them as a vehicle for “tourist chumps.”
Business Insider reports that OpenAI isn’t the only major AI company looking to crack down on SPVs, with Anthropic reportedly telling Menlo Ventures it must use its own capital, not an SPV, to invest in an upcoming round.



The Largest Survey of Exoplanet Spins Confirms a Long-held Theory
For some time, astronomers have theorized that there is a connection between planetary mass and rotation. In the Solar System,...


UH Mānoa hosts Vietnam War survivor story
Reading time: 2 minutes One of many pairs of well worn baby shoes worn by orphans evacuated from Vietnam during...


Brooks Nader and Taron Egerton kiss during LA date night
Brooks Nader and Taron Egerton once again couldn’t keep their hands off each other during a date night in Santa...


Woman in critical condition after stabbing in downtown L.A.; suspect arrested
A woman in downtown Los Angeles was hospitalized in critical condition on Tuesday after police say she was stabbed in...


Chelsea vs Arsenal LIVE: Latest updates from UWCL quarterfinal
Chelsea host Arsenal in the second leg of this all-English Women’s Champions League quarterfinal, and you can follow all the...
Iran Maintains Nuclear Capacities Despite Trump’s Claim of U.S. Success
For the second time in recent days, President Trump declared that one of the key objectives of the war had...


Patriots’ Mike Vrabel doesn’t dismiss A.J. Brown trade talk
Mike ReissMar 31, 2026, 12:54 PM ET Close Mike Reiss is an NFL reporter at ESPN and covers the New...


Roseanne Barr reveals heart issue, fears she’ll die during surgery
Roseanne Barr received a stark diagnosis — a “damaged” heart — a warning that left her fearing she could “die on...


KYTHERA Mission Concept Targets 200-Day Mission to Venus Surface
The planet Venus is often called “Earth’s twin” due to the similar sizes, but the reality couldn’t be farther from...


Nathan Lane and Marc Shaiman Perform on LATE NIGHT WITH STEPHEN COLBERT
Acclaimed actor Nathan Lane appears on tonight’s episode of Late Night with Stephen Colbert. As part of his appearance, Lane,...


Sheryl Lee Ralph Serves Beauty And Body In A Bikini While In Jamaica
John Parra/Getty Images for Sandals Resorts Could 69 be the new 49? Looks like it! Sheryl Lee Ralph, 69, is...


Indecent exposure case at Whole Foods in Valencia under investigation
What began as a routine day of shopping in Valencia quickly turned into a disturbing encounter that has prompted a...


Kendra Duggar hires lawyer as aunt urges divorce and parents break silence on Joseph arrest
Kendra Duggar reveals she hired her own lawyer in a jail call with husband Joseph as new details emerge in...
Woodward Diversified Capital Boosts Stake in ProShares Ultra QQQ ETF
Got story updates? Submit your updates here. › Woodward Diversified Capital LLC, an Oklahoma-based investment management firm, significantly increased its...
Trump Faces a Decision on Whether to Start a Ground War in Iran
The president wants a negotiation, but the Iranians say they are refusing until a cease-fire is declared. And while Marines...


Amanda Peet exposes ‘desperation galore’ behind Hollywood fame
Amanda Peet is pulling back the threadbare curtain on life underneath the spotlight. The 54-year-old actress called out Hollywood as nothing...


Nixon doesn’t look so bad after all – Daily Freeman
It’s hard for me to describe how much I once loathed Richard Nixon. As a college student during the Watergate...


Oldest Carbon-rich Stars Open a Window to Early Cosmic Chemistry
Astronomers studying the ultra-faint dwarf galaxy Pictor II have found an extremely chemically peculiar star that contains traces of elements...


Lionel Richie warns rising stars to embrace fans after bizarre Chappell Roan incident
NEWYou can now listen to Fox News articles! Lionel Richie knows the fame game can be a challenge, and issued...


As fourth man dies at Adelanto ICE detention center, Mexican officials call for investigation
A Southern California immigration detention center faces renewed scrutiny after federal officials confirmed the death of a detainee last week,...


Charlie Puth details his new album with Page Six Radio
Taylor Swift declared Charlie Puth should be a bigger artist, and now she’s in luck. The musician is releasing new...
Access Denied
Access Denied You don’t have permission to access “http://www.ndtv.com/world-news/iran-war-news-tehran-speaker-mohammad-bagher-ghalibaf-on-how-to-make-money-from-trumps-mood-swings-11285476” on this server. Reference #18.cca31002.1774891070.6b10232 https://errors.edgesuite.net/18.cca31002.1774891070.6b10232 Source link
How a Civics School With a Conservative Bent Divided Its Supporters
A University of North Carolina program was intended to promote civil discourse and ideological diversity. Some of its early conservative...


RDU’s Terminal 1 evacuated after threat :: WRAL.com
Raleigh-Durham International Airport’s Terminal 1 was evacuated early Monday after receiving an anonymous threat just before 4:30 a.m., airport officials...


Arnold Schwarzenegger’s look-alike son, Joseph Baena, wins first bodybuilding competition
Just call them twins. Arnold Schwarzenegger’s look-alike son Joseph Baena proved the apple doesn’t fall too far from the tree...


Solar Activity Could Threaten the Artemis Crew
In his blockbuster 1982 novel “Space”, the writer James A. Michener wove a gripping tale of astronauts trapped on the...


Rumors: Warriors will re-sign Kristaps Porzingis, try to make bold move this offseason
Stephen Curry may return to the court this season and help the Warriors to make a push to get out...


Swalwell accuses Trump of trying to influence California governor’s race with old FBI files
Rep. Eric Swalwell, a leading Democratic candidate for governor of California, has accused President Trump of trying to sway the...


Caleb Durbin Reveals Where He Ranks Making His Red Sox Debut Among His Career Milestones
The Boston Red Sox acquired Caleb Durbin from the Milwaukee Brewers this offseason, and he revealed where his Red Sox...


Kim Kardashian accused of heavily editing Khloé’s face in photos from Japan trip
Another Photoshop fail? Kim Kardashian was called out by fans for heavily editing her sister Khloé Kardashian’s face in new...


Olivia Munn, Winnie Harlow, Jessica Simpson, Kevin Hart and more
Star snaps of the week: Olivia Munn, Winnie Harlow, Jessica Simpson, Kevin Hart and more Birdie Mae Johnson (left) and mom...
Confronting the Chaos
We offer some suggestions to help you get started on spring cleaning.


Ollie Bearman explains why Kimi Antonelli’s first F1 win was “very special”
Ollie Bearman has branded Kimi Antonelli’s maiden Formula 1 win as “very special”. The Briton watched his former Formula 2...


Blocking out the Stellar Lighthouses
Finding another Earth is one of the greatest scientific challenges of our time and the biggest obstacle isn’t the distance,...


Martin Short seen in first public outing since daughter Katherine’s sudden death
Martin Short wore a serious expression while stepping out in Santa Monica — his first public outing since his daughter...


Canadiens at Predators projected lineups
CANADIENS (40-21-10) at PREDATORS (34-29-9) 7 p.m. ET; FDSNSO, SNE, CITY, TVAS Canadiens projected lineup Cole Caufield — Nick Suzuki...


‘No Kings’ rallies draw millions protesting Trump globally
A rolling wave of “No Kings” protests swelled through America’s small towns and big cities Saturday, with crowds gathering to...


Fan Information for Saturday’s Nebraska Football Spring Game – University of Nebraska
Below is information for fans in advance of Saturday’s Red-White Spring Game presented by FNBO. Tickets & Seating Fans are...


‘RHOSLC’ star Mary Cosby questioned by police about son’s alleged violence weeks before his death: report
Mary Cosby was questioned by authorities about her son Robert Cosby Jr.’s alleged domestic violence incident just weeks before his...
Is Iran a Political Problem for Trump? Tell Me How Long the War Lasts.
Historically, quagmire abroad and high prices at home are the ingredients of a failed presidency.


Kanye West drops new album ‘Bully’ on YouTube – How to listen
Ye apologizes, says he’s not ‘an antisemite’ in full-page newspaper ad Ye, formerly known as Kanye West, wrote, “I am...


Mars-Like Worlds Near M-Dwarfs May Lose Air in Millions of Years
The criteria for finding an Earth-like planet unofficially comes down to two things: water and the habitable zone. But a...


SmackDown: March 27, 2026 | WWE
On Friday, Jelly Roll will step back into the squared circle for the first time since SummerSlam to take on...


Zohran Mamdani was pitched to SNL, but they passed for someone funny
Mayor Zohran Mamdani almost made it onto New York’s most famed sketch show where the notably inexperienced politician could have...


Early spring storms bringing snow to California, drizzle to Los Angeles
The storm season isn’t over just yet, as an early spring system headed for California is expected to bring snow...


H-1B lottery 2027 update: Immigration lawyers predict registration number to be around 200K this year
Immigration attorneys predict that the H-1B registrations this year (FY 2027) will be around 200K. Immigration lawyers predict that the...
United Airlines Flight Avoids Collision With Military Helicopter in California
The Federal Aviation Administration said it was investigating after a helicopter crossed into the path of United Airlines Flight 589.


Savannah Guthrie vows not to ‘fall apart’ for kids’ sake amid mom Nancy’s disappearance
Savannah Guthrie promised not to “fall apart” for the sake of her two children during her “Today” show interview on...


Sony Cancels Popular ‘Spider-Man’ Project After Years of Success
For years, the relationship between Marvel Studios and Sony Pictures has felt like a balancing act—one that fans have watched...


How to buy Arizona vs. Purdue Elite 8 tickets, March Madness tickets
No. 1 seed Arizona is headed to the Elite Eight, and the Wildcats looks good doing it. As a favorite...


Uncovering the Effects of Microgravity on Liver Metabolism
The liver plays a vital role in human health, regulating metabolism and blood nutrient levels, filtering toxins, and synthesizing important...


Antonio Banderas reveals why he fled Hollywood after major health scare
Antonio Banderas gave up his ritzy Hollywood lifestyle and has zero regrets almost 10 years later. The actor, 65, moved...


Surinam espera alrededor de 50 fans para repechaje en Monterrey
25 de mar, 2026, 19:16 ET El equipo de Henk Ten Cate contará con un apoyo reducido en las gradas...


El Segundo father arrested after installing unauthorized stop signs near children’s park
A longtime El Segundo resident was arrested earlier this month after installing unauthorized stop signs at a neighborhood intersection he...


NASA astronaut posted a photo on social media of a bizarre object growing in space
Solar activity can be dangerous to astronauts in space. As Artemis II prepares to launch on April 1, NASA will...
Men of the Trump Administration, 2026
Are Democrats ugly? Asking for a friend.


Pussycat Dolls’ Jessica Sutta claims her MAGA politics cost her a reunion tour
Former Pussycat Dolls member Jessica Sutta is speaking out after being excluded from the girl group’s upcoming reunion tour, saying...


How the new WNBA CBA will impact every player’s salary in 2026
Michael VoepelMar 21, 2026, 05:23 PM ET Close Michael Voepel is a senior writer who covers the WNBA, women’s college...
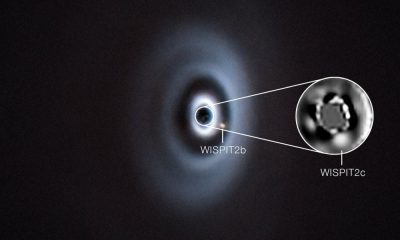

Direct Confirmation Of Two Baby Planets Forming Around A Young Sun-like Star
As the number of exoplanet detections has breached 6,000 and continues to grow, scientists are finding a wide variety of...


Game Preview #73 – Timberwolves vs. Rockets
Minnesota Timberwolves vs. Houston RocketsDate: March 25th, 2026Time: 8:30 PM CDTLocation: Target CenterTelevision Coverage: ESPN, FanDuel Sports Network – NorthRadio...


Why Savannah Guthrie’s emotional tell-all interview has kidnapper ‘terrified’: expert
Savannah Guthrie’s heart-wrenching “Today” interview with Hoda Kotb could leave her mom Nancy Guthrie’s kidnapper “terrified” as more eyes are...


Wannabe Kim Kardashian died from lethal butt injections. Her injector was just convicted
A Florida woman faces years in prison after she flew to the Bay Area and met a woman in a...


Can Pegula snap skid vs. Rybakina?
MIAMI — With Coco Gauff and Karolina Muchova booking their spots n the semifinals of the Miami Open Tuesday, the...
N.Y.U. Professors Reach a Deal on a Contract to End Strike After 2 Days
A union for about 950 full-time faculty members who are not on the tenure track said that 95 percent of...


New Purple Alert system activated for first time in Smithfield missing teen case
CRANSTON, R.I. (WJAR) — A new alert system in Rhode Island, designed to notify the public when adults with disabilities...


Best Amazon Big Spring Sale 2026 beauty deals: Dyson, Medicube, more
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Mars Plant Growth from Cyanobacteria-Based Fertilizer
You’re the Lead Botanist on the third human mission to Mars whose primary job involves growing food for the crew...


Injury Notes: Brooks, Williams, Ivey, Embiid, Shamet
By Rory Maher | at March 23, 2026 6:56 pm The Suns could get a couple of starters back from...


Providence hires Bryan Hodgson: Friars tap USF coach to replace Kim English
Getty Images Bryan Hodgson: Friar. Providence hired the 38-year-old to be the next coach of its men’s basketball program, the...


Donkeys are being shot with arrows in the Inland Empire. There’s a $50,000 reward to find the culprit
Animal activists are offering a $50,000 reward for information that leads to the arrest of whoever is shooting donkeys with...


Sydney Sweeney wears sheer lingerie to the theater in sizzling Syrn video
Sydney Sweeney shared a seductive behind-the-scenes video on Instagram Tuesday to accompany her Syrn lingerie line’s latest release. Instagram/@syrn Sydney...


Savannah Guthrie could return to ‘Today’ show next month
Savannah Guthrie could be back in her chair in just a few weeks. A source tells Page Six that while...
Plane Crash Kills 66 From Military and Police in Colombia
A military aircraft transporting 128 troops and crew members was in an accident as it took off from southern Colombia,...

Stocks catch up with BTC’s earlier crash to $60,000 as bond yields surge
Bitcoin BTC$70,469.59 began the year on a painful note, even as equity markets remained buoyant. But stock traders’ luck is...


How to watch the ‘Hannah Montana’ 20th anniversary special
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Giant Craters May Reveal if Psyche is a Lost Planetary Core
When we think of asteroids, we almost immediately think of giant rocks bouncing around like the iconic chase scene in...


Under the Hood: Dominant Duren
Under the Hood – it’s time to see what’s really going on inside this Pistons team. Look, I’ve been slacking...


LAUSD moves to strip César Chávez’s name from two campuses and change focus of holiday
Officials are moving Tuesday to strip the name of César Chávez from two Los Angeles school district campuses as fallout...


‘Superman’ star Valerie Perrine dead at 82 after Parkinson’s battle
Valerie Perrine, the actress best known for her role in the Christopher Reeve “Superman” movies, has died. She was 82....


ATP Miami Best Bets Including Daniil Medvedev vs Francisco Cerundolo
The ATP Masters 1000 Miami 1/16-finals keep offering some clear reads. Humbert has both the H2H edge and fresher legs,...
Diabetes, Overlooked and Unchecked, Poses New Risks in Africa
As deaths from diabetes start to rival those from infectious threats like malaria, a new form of the condition linked...


Day 23 of Middle East conflict — Iran responds to Trump threat to bomb power plants, strikes on Israel
Habima Square is right in the heart of Tel Aviv. Hours after a suspected bomblet from an Iranian cluster missile...


This Pair Of Brown Dwarfs Can’t Get Enough Of Each Other
Binary stars are known to transfer mass to one another. In extreme cases, mass transfer can even cause a supernova...


Justin Timberlake jokes about his race being labeled as ‘white’ in Hamptons DWI arrest video
Justin Timberlake was quite the comedian after being arrested in the Hamptons for DWI. Footage of the singer’s June 2024...


Minnesota Timberwolves vs Golden State Warriors Mar 13, 2026 Box Scores
Navigation Toggle Home Tickets Key Dates 2025-26 Regular Season Schedule National TV Games Emirates NBA Cup Schedule League Pass Schedule...


Trump border advisor says ICE to deploy to U.S. airports Monday
What began as a social media post from President Trump on Saturday has grown quickly into a full-scale plan to...


Koepka ‘thankful’ after girl escapes injury in golf-cart incident
The Valspar Championship was temporarily halted during Saturday’s third round when a young spectator was struck by a golf cart....


Chappell Roan responds to explosive allegations she made Jude Law’s daughter cry
Chappell Roan denied explosive allegations that she made Jude Law’s minor daughter cry during an interaction in Brazil. “I’m just...


Lea Michele sets departure from ‘Chess’ on Broadway
It’ll be someone else’s story soon. Emmy Award nominee Lea Michele will depart Chess on Broadway on June 21. A...
Who Is Antigone? The 2500-Year-Old Rebel With a Cause.
“Antigone” gave us the original “bad girl,” but its themes go beyond that. How do adaptations keep making Sophocles’ ideas...


Saturday 3/21/26 Powerball $120 million jackpot winning numbers
Video: What would you do if you won Powerball jackpot $1.7 billion ? Players buy tickets for the $1.7 billion...


How Will Martian Gravity Affect Skeletal Muscle?
NASA and the China National Space Agency (CNSA) plan to send astronauts to Mars as early as the next decade....


Shia LaBeouf shouts at woman in Rome in video footage
Shia LaBeouf was once again spotted shouting erratically in video footage from Rome. In video obtained by TMZ on Saturday,...


CBS Analyst Makes Bold Claim About Kelvin Sampson and the Houston Cougars
As many predicted, the No. 2-seed Houston Cougars dominated the No. 15-seed Idaho Vandals in the first round of the...


Riverside County Sheriff Chad Bianco seizes more than half a million ballots
Riverside County Sheriff Chad Bianco, who is a leading Republican candidate for governor, has seized more than 650,000 ballots from...


The Case for Custom eLearning Platforms: Why Organizations Are Making the Switch
The corporate eLearning market has exploded in recent years, growing over 800% since 2000. As the demand for eLearning continues...


‘I Cried Into the Nape of Her Neck’
Julia Fox has a message for those who “talk shit” about her: Beyoncé loves her. In fact, as Fox recalled...


Private Boat Tours and Water Taxi in Venice: The Most Elegant Way to Explore the City
Venice is unlike any other destination in the world. Built on a network of canals instead of roads, the city...


Who are Crypto Market Makers and Market Takers?
Understanding liquidity and trading dynamics is essential for those entering the cryptocurrency market. This knowledge helps young investors handle unpredictable...


Plan for Life’s Big Moments: Prepare for Unexpected Expenses with the BCU Financial Line of Credit
Life is full of unexpected situations, and as such, you should always be prepared for any financial emergencies that might...


Star snaps of the week: Jennifer Lopez, Mariah Carey, Shay Mitchell, Simone Biles and more
Alexandra Daddario gulps Champagne, Chris Pratt gets goofy and more snaps..


Restaurateur Max Chodrow is bringing his hip Jean’s bistro to the Hamptons
New York’s hip Jean’s restaurant is getting a new address out East. Restaurateur Max Chodrow is taking over Hamptons classic,...


Josh Duggar speaks out on brother Joseph Duggar child molestation arrest
Former reality star turned convicted sex offender Josh Duggar slammed the “false accusations” against his brother, Joseph Duggar, who was...


Rebecca Gayheart has split from Peter Morton
Rebecca Gayheart and her mega-mogul boyfriend Peter Morton quietly split last year, sources tell Page Six, parting ways before the...


Uma Thurman reveals why she never lived in Los Angeles remaining in New York
Uma Thurman built an A-list career without ever planting roots in Hollywood, and the actress exclusively told InStyle that skipping Los...


Judy Garland’s daughter, Lorna Luft, says Dorothy was ‘always for my mom,’ not Shirley Temple
Judy Garland was “always” meant to sing “Somewhere Over the Rainbow,” despite a longtime rumor that Shirley Temple was considered...


Christina Haack wows in cream-colored crochet bikini after addressing rumors she’s engaged for fourth time
Christina Haack is shaking off the rumors and soaking up the sun. “The Flip Off” star turned heads on Instagram...


Hailey Bieber wears lingerie dress to Beyoncé’s Oscars 2026 afterparty
Hailey Bieber wore a sheer The Attico slip dress to Jay-Z and Beyoncé’s post-Oscars party at Chateau Marmont. Hailey Bieber...


Comedian Bert Kreischer thanks God after devastating tour bus fire that could have killed him
Bert Kreischer counted his blessings after narrowly avoiding disaster. The comedian was grateful to be safe Sunday after his bus...


Sarah Pidgeon honors Carolyn Bessette Kennedy in Calvin Klein on the Vanity Fair Oscars Party 2026 red carpet
Sarah Pidgeon wore custom Calvin Klein at the Vanity Fair Oscar Party 2026. FilmMagic Sarah Pidgeon is finally slipping into...


Oscars 2026 best and worst moments
The 2026 Oscars was one to remember on Sunday, with Conan O’Brien returning for his second consecutive year as host...


Harry Styles hits back at ‘queerbaiting’ claims — by kissing male comedian during ‘SNL’ monologue
Harry Styles hit back at claims that he is “queerbaiting” by kissing comedian Ben Marshall during the singer’s “Saturday Night...


Zendaya makes surprise Las Vegas wedding appearance
Zendaya crashed a Las Vegas wedding while promoting her latest movie, further fueling rumors she’s already married to Tom Holland....


Queen Camilla told friend Meghan Markle ‘brainwashed’ Harry amid royal family feud, new book claims
Queen Camilla privately told a friend that Meghan Markle had “brainwashed” Prince Harry amid the royal family’s feud, according to...


We tried the buttery soft style
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Cindy Crawford roasted over morning routine
Cindy Crawford’s morning rituals not for the faint-hearted. The 60-year-old supermodel has stunned her followers by revealing her 2.5-hour routine,...


I tried Scarlett Johansson’s new skincare
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Kelly Clarkson reveals ‘lying’ ‘American Idol’ stiffed her on $1 million prize, new car
Kelly Clarkson accused “American Idol” of “lying” about the $1 million check that she was supposed to receive after becoming...


William Shatner to undergo surgery following terrifying horse accident
He’s about to go where many men have gone before – the operating room. William Shatner revealed that he shattered...


‘Lost’ star Matthew Fox reveals why he walked away from Hollywood at height of his stardom
Matthew Fox was at the top of Hollywood — and then he walked away. The “Lost” star, now 59, stepped...


Jax Taylor, Brittany Cartwright finally reach custody agreement 2 years post-split
Jax Taylor and Brittany Cartwright have finally settled custody of their son, Cruz, nearly two years after separating. The “Vanderpump...


Michelle Pfeiffer, Kurt Russell, Kelsea Ballerini and more
“The Madison”, the new Taylor Sheridan Western series, held its New York premiere at Lincoln Center on Mar. 9. Stars...


Hermès reportedly refused to sell North West a rare Kelly bag
North West’s got a massive designer wardrobe at her disposal — but some styles are still out of reach, it would...


Meghan Markle shares rare photo of Lilibet taken by her dad Harry in honor of International Women’s Day
Meghan Markle honored her daughter, Lilibet, on International Women’s Day with a sweet photo taken by her father, Prince Harry....


Ousted CBS anchor Josh Elliott and wife Liz Cho locked in nasty divorce battle after a decade of marriage
Former CBS anchor Josh Elliott has filed for divorce from his wife, Liz Cho, after nearly a decade of marriage...


‘Will & Grace’ alum dead at 60 after cancer battle
“Will & Grace” star Corey Parker has died. He was 60 years old. The actor’s aunt, Emily Parker, revealed the...


‘RuPaul’s Drag Race’ Season 18 Episode 10 recap
“Werk Room Weekly” returns to break down “RuPaul’s Drag Race” Season 18, Episode 10, and there’s plenty to unpack before...


Actor who played The Gimp in ‘Pulp Fiction’ dead at 68
Stephen Hibbert, best known for playing The Gimp in “Pulp Fiction,” has died at 68. The actor and writer died...
Beach Boys icon Bruce Johnston steps away from band after 60 years
After six decades with the Beach Boys, Bruce Johnston is taking a step back from the band. However, Johnston said he’s...


A timeline of Britney Spears’ troubled past
Britney Spears’ life has been filled with troubling moments, including her recent DUI arrest in California. The pop star was...


Twisted Sister taps ’80s metal icon to carry on legacy after frontman Dee Snider’s sudden exit
Twisted Sister is getting a heavy metal shake-up. The legendary hard rock band is moving forward without longtime frontman Dee Snider after...


Emily Ratajkowski handles Paris Fashion Week wardrobe malfunction like a pro before Dior
Emily Ratajkowski suffered two separate wardrobe malfunctions while at the Dior fashion show in Paris. AP Emily Ratajkowski suffered not...


Paris Hilton poses nude in bathtub photos showing off skincare brand Parivie Beauty
Paris Hilton posed in a bathtub for a selection of social media snaps to promote her skincare brand Parivie Beauty...


All the celebrities at Paris Fashion Week March 2026
We’ve finally reached the grand finale of a month’s worth of runway shows: Paris Fashion Week, where Dior, Chanel, Louis...


Jack Schlossberg eviscerates Ryan Murphy for his Kennedy-based series ‘Love Story’: ‘Grotesque’
Jack Schlossberg once again blasted Ryan Murphy for his Hulu series “Love Story,” which portrays the romance between the late...


Jack Schlossberg reveals sister Tatiana’s final words to him before tragic death
Jack Schlossberg revealed his late sister Tatiana Schlossberg’s last words to him were about his campaign. The 33-year-old aspiring congressman...


Irina Shayk brings the drama on SAG Actor Awards 2026 red carpet
Irina Shayk turned heads on the SAG Actor Awards 2026 red carpet. Kevin Mazur/Getty Images Irina Shayk’s latest look fits...


Star snaps of the week: Jessica Alba, Kevin Hart, Brooke Shields and more
Lisa Rinna gets carried to her car, Meghan Markle shoots her shot and more.


Ioan Gruffudd claims ex-wife Alice Evans threatened to ‘Amber Heard’ him as dramatic trial kicks off
Ioan Gruffudd testified that his ex-wife, Alice Evans, threatened to destroy his career by making false, explosive accusations against him....


Kylie Jenner looks visibly uncomfortable at Alan Cumming’s cheeky joke at BAFTAs
Kylie Jenner was visibly uncomfortable when host Alan Cumming made a rather cheeky joke at the 2026 BAFTAs Sunday. During...


Jennifer Lopez celebrates twins Emme and Max’s 18th birthday with sweet tribute
Jennifer Lopez shared an emotional tribute to her twins, Max and Emme, on their 18th birthday. The singer and actress...


Tim McGraw reveals most controversial song Indian Outlaw after industry tried to cancel hit
Tim McGraw is looking back at the most “controversial” song of his career. During a recent interview on “The Tim Ferriss...


Oprah’s Roomy Cargo Pants Are a Go-To Fall Style
Welcome to The Blueprint, where we break down the celebrity looks we want to wear right now and build them...


Karlie Kloss welcomes third baby with husband Joshua Kushner
Karlie Kloss’ brood just got bigger. The model has given birth to her and husband Joshua Kushner’s third baby —...


Prince Harry Made Secret Visit to Another Member of Royal Family During U.K. Trip
NEED TO KNOW Prince Harry’s four-day visit to the U.K. included a secret visit to another member of the royal...


Matthew McConaughey reveals the bedroom secret that helped his marriage
Bigger isn’t always better. Matthew McConaughey revealed in his new book that downsizing his bed helped him get closer to...


Jordin Sparks Reveals If Son DJ, 7, Wants to Become a Singer
NEED TO KNOW Jordin Sparks attended the Elizabeth Taylor Night of Compassion at the Beverly Hills Hotel in California on...


Norman Reedus’ son makes alarming threat after arrest for assault
Norman Reedus and supermodel Helena Christensen’s troubled son, Mingus Reedus, asked a startling question one day after he was arrested...


Where Is Paula Deen Now? Inside the Celebrity Chef’s Life After Food Network
NEED TO KNOW It has been over a decade since Paula Deen’s Food Network show came to an end in...


Sydney Sweeney’s ‘Americana’ co-star Halsey slams fans who boycotted film over ‘denim bulls–t’
Sydney Sweeney’s “Americana” co-star Halsey slammed fans who are boycotting their film due to the former’s American Eagle controversy. “you...


Milla Jovovich Gushes Over Paul W.S. Anderson in 16th Wedding Anniversary Tribute
NEED TO KNOW Milla Jovovich and her husband, Paul W.S. Anderson, are celebrating 16 years of marriage with a series...


Ozzy Osbourne ‘knew’ he was dying during final Black Sabbath show
When a “frail” Ozzy Osbourne took the stage for his final Black Sabbath show, he knew the end was coming....


See Photos of Pierce Brosnan, Colin Farrell, Margot Robbie, Anne Hathaway and More
Stars have been everywhere this week, from Pierce Brosnan looking as dapper as ever in London to Margot Robbie and...


Meghan Markle sending ‘intentional’ message to royals with calculated move on Season 2 of Netflix show
Meghan Markle is allegedly sending an “intentional” message to the royals with her fashion choices for Season 2 of her...


Jillian Michaels Slams ‘Egregious’ Claims in ‘The Biggest Loser’ Documentary
NEED TO KNOW Jillian Michaels is denying claims made against her in Netflix’s docuseries Fit for TV: The Reality of...


Joan Collins, 92, defies age in chic white swimsuit on vacation
Age is just a number. Joan Collins flaunted her “timeless beauty” in a chic white swimsuit as she shared a...


See Photos of Kaitlyn Dever, Pedro Pascal, Cynthia Erivo and More
Stars have been everywhere this week. Kaitlyn Dever and Pedro Pascal attend the HBO Max Emmy Nominee Celebration in Hollywood,...


Livvy Dunne talks to Page Six about being a Taylor Swift fan
Gymnast and social media star Livvy Dunne is a certified Swiftie. Dunne, who is dating Pirates All-Star pitcher Paul Skenes,...


Bella Thorne Reacts After Fans Criticized Her for Proposing to Fiancé Mark Emms
NEED TO KNOW Bella Thorne responded after fans criticized her for proposing to her fiancé, Mark Emms, two years after...


Kate Middleton and Prince William’s new home forces 2 families to ‘move out’: report
Kate Middleton and Prince William’s new family mansion reportedly forced two families to move out of their nearby homes. The...


Seth Green Teases a DuJour Reunion from ‘Josie and the Pussycats’
NEED TO KNOW In an interview, Seth Green recently said he would be open to a DuJour reunion DuJour is...


Courtney Stodden takes new swipe at Chrissy Teigen four years after cyberbullying scandal
Courtney Stodden claims she sent a friendly message to Chrissy Teigen, but she’s being “completely ignored” four years after their...


Mila Kunis Says She Barely Ate During Prep for ‘Black Swan’ Role
NEED TO KNOW Mila Kunis is recounting her intense preparation for her role as a professional ballerina in Black Swan...


Gal Gadot says ‘pressure’ to speak out against Israel caused ‘Snow White’ movie to flop
Gal Gadot revealed she believes the “pressure” placed on celebrities to speak against Israel played a role in her Disney...


Peacemaker’s Jennifer Holland on Work-Life Balance in Marriage to Creator James Gunn (Exclusive)
NEED TO KNOW Peacemaker actress Jennifer Holland opens up about the work-life balance in her relationship with series creator James...


Pierce Brosnan reveals the secret behind his great head of hair and aging well
Pierce Brosnan may be unlocking the secret to why Irish men seem to possess enviable mops of hair. “I don’t...


Viola Davis Shares Photos from Her 60th Birthday Celebration Vacation
NEED TO KNOW Viola Davis celebrated her 60th birthday in Cabo San Lucas, Mexico The Oscar-winning actress marked the milestone...


Kate Gosselin snubs estranged son Collin, says her kids ‘all get along’ and have ‘wonderful’ bond
Kate Gosselin gushed over how well her children “get along” after her estranged son, Collin, penned an emotional open letter,...


Johnny Knoxville, 54, Shows Off Buff Arms While Hitting the Speed Bag
NEED TO KNOW Johnny Knoxville showed off his skills — and some serious biceps — on the speed bag in a...


Quinn XCII answers questions about his new album ‘LOOK! I’m Alive’ in Confession Cube
Quinn XCII answers questions about his new album ‘LOOK! I’m Alive’ in Confession Cube Next Previous


Katie Holmes Wore a Flannel with Trousers, Shop the Look
Welcome to The Blueprint, where we break down the celebrity looks we want to wear right now and build them...


Dua Lipa flaunts her abs during paddleboard yoga in Ibiza
Dua Lipa is showing off her impressive abs and athletic ability in Ibiza. The singer, 29, was snapped doing yoga...


Does Kim Cattrall Return as Samantha?
Warning: This story contains spoilers for the And Just Like That… series finale. NEED TO KNOW Fans have been wondering...


Olivia Jade Giannulli is the spitting image of mom Lori Loughlin in first sighting since Jacob Elordi split
Like mother, like daughter. Olivia Jade Giannulli looked like her mom Lori Loughlin’s twin in her first sighting since her...


How Prince William, Prince Harry Impact Diana’s Causes 28 Years After Her Death
NEED TO KNOW Prince William and Prince Harry are separately backing causes that Princess Diana championed during her life Tessy...


Taylor Swift details emotional moment that left her and Travis Kelce ‘weeping’
Travis Kelce comforted Taylor Swift as she fought back tears while discussing the dramatic moment she found out she would...


Taylor Swift Reflects on Taking Care of Her Dad After His Heart Surgery
NEED TO KNOW Taylor Swift opened up about her dad Scott Swift’s major quintuple bypass surgery Swift revealed she moved...


Taylor Swift’s new album ‘Life of a Showgirl’: Everything to know
Taylor Swift sent shockwaves through her fandom by announcing her 12th studio album during her debut appearance on boyfriend Travis...


Luke Bryan Slams ‘Idiots’ Throwing Objects at Musicians During Concerts
NEED TO KNOW Luke Bryan has some words for “idiots” who throw objects at musicians during shows In July, the...


Taylor Swift gets cozy with Travis Kelce and teases ‘male sports fans’ in ‘New Heights’ preview
Taylor Swift gets cozy with Travis Kelce and teases ‘male sports fans’ in ‘New Heights’ preview Next Previous


Naomi Watts Wore Wide-Leg Jeans Like These Pairs from Amazon
Celebrities have been reaching for roomy, breezy pants all summer long — and it doesn’t look like the comfortable trend...


Blake Lively takes swipe at Justin Baldoni’s lawyer over alleged ‘smear campaign’ in deposition transcript
Blake Lively took a swipe at Justin Baldoni’s lawyer, Bryan Freedman, during her July 31 deposition, accusing him of being...


Jessica Alba Wore a Cardigan and Trousers, Get the Look
Welcome to The Blueprint, where we break down the celebrity looks we want to wear right now and build them...


Dua Lipa celebrates 30th birthday in sequin dress with a butt cutout
Dua Lipa celebrated her 30th birthday early in a custom white dress with a butt cutout. Instagram/dualipa Bootylicious. Though Dua...


Taylor Swift Announces New Album The Life of a Showgirl with Help from Travis and Jason Kelce
NEED TO KNOW Taylor Swift has revealed her next era will be The Life of a Showgirl The announcement came...


Taylor Swift announces new album ‘Life of a Showgirl’ on ‘New Heights’ podcast
Drop everything now! Taylor Swift announced she’s releasing new music during a surprise appearance on her boyfriend Travis Kelce’s “New...


Bethenny Frankel Admits She’s Currently ‘Afraid’ to Date
NEED TO KNOW Bethenny Frankel opened up about her dating life in a candid TikTok In the video, Frankel shares...


Lauren Sánchez marks a major parenting milestone as son Evan goes to college
Lauren Sánchez felt “proud,” but also “heartbroken,” as she dropped her son, Evan Whitesell, off at college. The former journalist...


Jennifer Aniston Makes Rare Comments About Her Divorce from Brad Pitt
NEED TO KNOW Jennifer Aniston gave some rare comments about her divorce from Brad Pitt in her newly published September...


Exes Joe Jonas and Demi Lovato reunite for ‘Camp Rock’ performance
The band is all here. Exes Joe Jonas and Demi Lovato stunned fans when they reunited for a “Camp Rock”...


Maluma Stops Concert to Scold Mom Who Brought Baby
NEED TO KNOW Maluma called out a fan for bringing a baby to his Mexico City concert “Do you think...


Kathy Griffin confirms third facelift after raising eyebrows with ‘very taut’ appearances
Kathy Griffin confirmed she underwent a third facelift after making headlines due to her recent public appearances. The 64-year-old comedian...


Singer Says He’ll ‘Never Play in Kansas City’
NEED TO KNOW Zach Bryan said he “will never play in Kansas City” while feuding with Kansas City Chiefs fans...


‘Doomsday prepper’ Josh Duhamel reveals ‘calling’ that made him leave LA for Minnesota
Livin’ life in the “Land of 10,000 Lakes.” “Doomsday prepper” Josh Duhamel revealed that he was inspired to leave Los...


Linda Hamilton Is ‘Uncomfortable’ with Praise, Being Told She’s an ‘Icon’ (Exclusive)
NEED TO KNOW Linda Hamilton sometimes ran into a starstruck response while on set for her new film Osiris, she...


Kate and Jon Gosselin’s son Collin pens message to estranged siblings
Kate and Jon Gosselin’s son Collin released an emotional open letter to his seven siblings. The “Jon & Kate Plus...


‘TMNT’ Co-Creator Reveals Which Actor Wants to Play Casey Jones (Exclusive)
NEED TO KNOW Teenage Mutant Ninja Turtles co-creator Kevin Eastman said that actor Joe Manganiello would like to play Casey...


‘DWTS’ alum Cheryl Burke reveals how she dropped 41 pounds
Cheryl Burke lost a significant amount of weight — while still enjoying the sweeter things in life. “At my heaviest...


Melissa McCarthy and Husband Ben Falcone Recreate ‘Ghost’ Pottery Scene
NEED TO KNOW Melissa McCarthy and husband Ben Falcone visited Wild Clay L.A. on Friday, Aug. 8 They shared a...
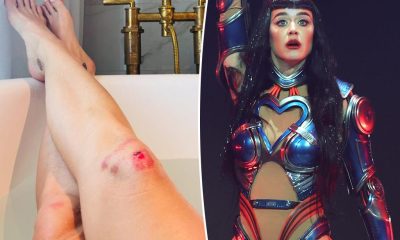

Katy Perry shows off brutally scraped knees she sustained during ‘Lifetimes’ tour
She’ll cry about it later. Katy Perry showed off her brutally scraped knees she sustained while dancing on her “Lifetimes”...
-

 News3 weeks ago
News3 weeks agoA Glorious Spiral of Star Formation
-

 News3 weeks ago
News3 weeks agoConvicted murderer who cut GPS ankle monitor caught after fleeing classes at Orange County college
-
News3 weeks ago
Mussolini Would Have Loved Trump’s Ballroom
-

 Trending3 weeks ago
Trending3 weeks agoMan seriously hurt in single-vehicle crash on Interstate 19 in Green Valley
-
Entertainment2 weeks ago
Restaurateur Max Chodrow is bringing his hip Jean’s bistro to the Hamptons
-

 Trending3 weeks ago
Trending3 weeks agoFranklin Resources Boosts Stake in DTE Energy
-

 Trending2 weeks ago
Trending2 weeks agoHow to watch Grizzlies vs. Bulls: TV channel and streaming options for March 16
-
Entertainment3 weeks ago
Cindy Crawford roasted over morning routine