
Technology
Open source LLMs hit Europe’s digital sovereignty roadmap

Large language models (LLMs) landed on Europe’s digital sovereignty agenda with a bang last week, as news emerged of a new program to develop a series of “truly” open source LLMs covering all European Union languages.
This includes the current 24 official EU languages, as well as languages for countries currently negotiating for entry to the EU market, such as Albania. Future-proofing is the name of the game.
OpenEuroLLM is a collaboration between some 20 organizations, co-led by Jan Hajič, a computational linguist from the Charles University in Prague, and Peter Sarlin, CEO and co-founder of Finnish AI lab Silo AI, which AMD acquired last year for $665 million.
The project fits a broader narrative that has seen Europe push digital sovereignty as a priority, enabling it to bring mission-critical infrastructure and tools closer to home. Most of the cloud giants are investing in local infrastructure to ensure EU data stays local, while AI darling OpenAI recently unveiled a new offering that allows customers to process and store data in Europe.
Elsewhere, the EU recently signed an $11 billion deal to create a sovereign satellite constellation to rival Elon Musk’s Starlink.
So OpenEuroLLM is certainly on-brand.
However, the stated budget just for building the models themselves is €37.4 million, with roughly €20 million coming from the EU’s Digital Europe Programme — a drop in the ocean compared to what the giants of the corporate AI world are investing. The actual budget is more when you factor in funding allocated for tangential and related work, and arguably the biggest expense is compute. The OpenEuroLLM project’s partners include EuroHPC supercomputer centers in Spain, Italy, Finland, and the Netherlands — and the broader EuroHPC project has a budget of around €7 billion.
But the sheer number of disparate participating parties, spanning academia, research, and corporations, have led many to question whether its goals are achievable. Anastasia Stasenko, co-founder of LLM company Pleias, questioned whether a “sprawling consortia of 20+ organizations” could have the same measured focus of a homegrown private AI firm.
“Europe’s recent successes in AI shine through small focused teams like Mistral AI and LightOn — companies that truly own what they’re building,” Stasenko wrote. “They carry immediate responsibility for their choices, whether in finances, market positioning, or reputation.”
Up to scratch
The OpenEuroLLM project is either starting from scratch or it has a head start — depending on how you look at it.
Since 2022, Hajič has also been coordinating the High Performance Language Technologies (HPLT) project, which has set out to develop free and reusable datasets, models, and workflows using high-performance computing (HPC). That project is scheduled to end in late 2025, but it can be viewed as a sort of “predecessor” to OpenEuroLLM, according to Hajič, given that most of the partners on HPLT (aside from the U.K. partners) are participating here, too.
“This [OpenEuroLLM] is really just a broader participation, but more focused on generative LLMs,” Hajič said. “So it’s not starting from zero in terms of data, expertise, tools, and compute experience. We have assembled people who know what they’re doing — we should be able to get up to speed quickly.”
Hajič said that he expects the first version(s) to be released by mid-2026, with the final iteration(s) arriving by the project’s conclusion in 2028. But those goals might still seem lofty when you consider that there isn’t much to poke at yet beyond a bare-bones GitHub profile.
“In that respect, we are starting from scratch — the project started on Saturday [February 1],” Hajič said. “But we have been preparing the project for a year [the tender process opened in February 2024].”
From academia and research, organizations spanning Czechia, the Netherlands, Germany, Sweden, Finland, and Norway are part of the OpenEuroLLM cohort, in addition to the EuroHPC centers. From the corporate world, Finland’s AMD-owned AI lab Silo AI is on board, as are Aleph Alpha (Germany), Ellamind (Germany), Prompsit Language Engineering (Spain), and LightOn (France).
One notable omission from the list is that of French AI unicorn Mistral, which has positioned itself as an open source alternative to incumbents such as OpenAI. While nobody from Mistral responded to TechCrunch for comment, Hajič did confirm that he tried to initiate conversations with the startup, but to no avail.
“I tried to approach them, but it hasn’t resulted in a focused discussion about their participation,” Hajič said.
The project could still gather new participants as part of the EU program that’s providing funding, though it will be limited to EU organizations. This means that entities from the U.K. and Switzerland won’t be able to take part. This flies in contrast to the Horizon R&D program, which the U.K. rejoined in 2023 after a prolonged Brexit stalemate and which provided funding to HPLT.
Build up
The project’s top-line goal, as per its tagline, is to create: “A series of foundation models for transparent AI in Europe.” Additionally, these models should preserve the “linguistic and cultural diversity” of all EU languages — current and future.
What this translates to in terms of deliverables is still being ironed out, but it will likely mean a core multilingual LLM designed for general-purpose tasks where accuracy is paramount. And then also smaller “quantized” versions, perhaps for edge applications where efficiency and speed are more important.
“This is something we still have to make a detailed plan about,” Hajič said. “We want to have it as small but as high-quality as possible. We don’t want to release something which is half-baked, because from the European point-of-view this is high-stakes, with lots of money coming from the European Commission — public money.”
While the goal is to make the model as proficient as possible in all languages, attaining equality across the board could also be challenging.
“That is the goal, but how successful we can be with languages with scarce digital resources is the question,” Hajič said. “But that’s also why we want to have true benchmarks for these languages, and not to be swayed toward benchmarks which are perhaps not representative of the languages and the culture behind them.“
In terms of data, this is where a lot of the work from the HPLT project will prove fruitful, with version 2.0 of its dataset released four months ago. This dataset was trained 4.5 petabytes of web crawls and more than 20 billion documents, and Hajič said that they will add additional data from Common Crawl (an open repository of web-crawled data) to the mix.
The open source definition
In traditional software, the perennial struggle between open source and proprietary revolves around the “true” meaning of “open source.” This can be resolved by deferring to the formal “definition” as per the Open Source Initiative, the industry stewards of what are and aren’t legitimate open source licenses.
More recently, the OSI has formed a definition of “open source AI,” though not everyone is happy with the outcome. Open source AI proponents argue that not only models should be freely available, but also the datasets, pretrained models, weights — the full shebang. The OSI’s definition doesn’t make training data mandatory, because it says AI models are often trained on proprietary data or data with redistribution restrictions.
Suffice it to say, the OpenEuroLLM is facing these same quandaries, and despite its intentions to be “truly open,” it will probably have to make some compromises if it’s to fulfill its “quality” obligations.
“The goal is to have everything open. Now, of course, there are some limitations,” Hajič said. “We want to have models of the highest quality possible, and based on the European copyright directive we can use anything we can get our hands on. Some of it cannot be redistributed, but some of it can be stored for future inspection.”
What this means is that the OpenEuroLLM project might have to keep some of the training data under wraps, but be made available to auditors upon request — as required for high-risk AI systems under the terms of the EU AI Act.
“We hope that most of the data [will be open], especially the data coming from the Common Crawl,” Hajič said. “We would like to have it all completely open, but we will see. In any case, we will have to comply with AI regulations.”
Two for one
Another criticism that emerged in the aftermath of OpenEuroLLM’s formal unveiling was that a very similar project launched in Europe just a few short months previous. EuroLLM, which launched its first model in September and a follow-up in December, is co-funded by the EU alongside a consortium of nine partners. These include academic institutions such as the University of Edinburgh and corporations such as Unbabel, which last year won millions of GPU training hours on EU supercomputers.
EuroLLM shares similar goals to its near-namesake: “To build an open source European Large Language Model that supports 24 Official European Languages, and a few other strategically important languages.”
Andre Martins, head of research at Unbabel, took to social media to highlight these similarities, noting that OpenEuroLLM is appropriating a name that already exists. “I hope the different communities collaborate openly, share their expertise, and don’t decide to reinvent the wheel every time a new project gets funded,” Martins wrote.
Hajič called the situation “unfortunate,” adding that he hoped they might be able to cooperate, though he stressed that due to the source of its funding in the EU, OpenEuroLLM is restricted in terms of its collaborations with non-EU entities, including U.K. universities.
Funding gap
The arrival of China’s DeepSeek, and the cost-to-performance ratio it promises, has given some encouragement that AI initiatives might be able to do far more with much less than initially thought. However, over the past few weeks, many have questioned the true costs involved in building DeepSeek.
“With respect to DeepSeek, we actually know very little about what exactly went into building it,” Peter Sarlin, who is technical co-lead on the OpenEuroLLM project, told TechCrunch.
Regardless, Sarlin reckons OpenEuroLLM will have access to sufficient funding, as it’s mostly to cover people. Indeed, a large chunk of the costs of building AI systems is compute, and that should mostly be covered through its partnership with the EuroHPC centers.
“You could say that OpenEuroLLM actually has quite a significant budget,” Sarlin said. “EuroHPC has invested billions in AI and compute infrastructure, and have committed billions more into expanding that in the coming few years.”
It’s also worth noting that the OpenEuroLLM project isn’t building toward a consumer- or enterprise-grade product. It’s purely about the models, and this is why Sarlin reckons the budget it has should be ample.
“The intent here isn’t to build a chatbot or an AI assistant — that would be a product initiative requiring a lot of effort, and that’s what ChatGPT did so well,” Sarlin said. “What we’re contributing is an open source foundation model that functions as the AI infrastructure for companies in Europe to build upon. We know what it takes to build models, it’s not something you need billions for.”
Since 2017, Sarlin has spearheaded AI lab Silo AI, which launched — in partnership with others, including the HPLT project — the family of Poro and Viking open models. These already support a handful of European languages, but the company is now readying the next iteration “Europa” models, which will cover all European languages.
And this ties in with the whole “not starting from scratch” notion espoused by Hajič — there is already a bedrock of expertise and technology in place.
Sovereign state
As critics have noted, OpenEuroLLM does have a lot of moving parts — which Hajič acknowledges, albeit with a positive outlook.
“I’ve been involved in many collaborative projects, and I believe it has its advantages versus a single company,” he said. “Of course they’ve done great things at the likes of OpenAI to Mistral, but I hope that the combination of academic expertise and the companies’ focus could bring something new.”
And in many ways, it’s not about trying to outmaneuver Big Tech or billion-dollar AI startups; the ultimate goal is digital sovereignty: (mostly) open foundation LLMs built by, and for, Europe.
“I hope this won’t be the case, but if, in the end, we are not the number one model, and we have a ‘good’ model, then we will still have a model with all the components based in Europe,” Hajič said. “This will be a positive result.”

Technology
The Case for Custom eLearning Platforms: Why Organizations Are Making the Switch

The corporate eLearning market has exploded in recent years, growing over 800% since 2000. As the demand for eLearning continues to accelerate, more and more organizations are finding that off-the-shelf solutions cannot keep pace with their training needs. This has led many companies to make the switch to custom-built eLearning platforms tailored specifically for their requirements.
There are several key reasons driving the demand for customized eLearning tools:
Greater Flexibility and Scalability
Generic eLearning software packages often impose rigid constraints that limit their ability to adapt to an organization’s evolving needs. Meanwhile, the “one-size-fits-all” approach fails to support the personalized learning critical for employee development. Custom platforms provide flexibility to add and modify features to match ever-changing business goals. As companies scale training across global workforces, custom solutions built on cloud infrastructure can scale seamlessly to handle growing demand.
Deeper Integration Across Systems
Smooth integration with existing HR, LMS, and other business systems is critical for optimizing training workflows. However, off-the-shelf tools rarely integrate well, creating data and process siloes. Custom platforms can tightly integrate role-based learning paths with core business applications, sync user profiles, enable single sign-on, and more. This level of integration catalyzes more impactful training function.
Better Data and Analytics
Generic software severely limits access to data insights that drive improvement. Custom platforms unlock a trove of analytics on content consumption, learner progression, platform adoption, and real-time feedback. Integrated analytics dashboards and APIs allow businesses to derive deep visibility across the learner lifecycle. These insights help continuously enhance learner experience, target development gaps, and demonstrate direct training ROI.
Enhanced Learner Engagement
For modern learners accustomed to consumer-grade digital experiences, poor platform usability quickly erodes engagement. Custom designs allow companies to incorporate familiar features from popular apps and websites while optimizing for their audience. Adaptive learning approaches further personalize content to individual styles and needs. With modular component architecture, custom platforms stay on the cutting edge of new modalities like AR/ VR to captivate learners.
Brand and Culture Alignment
Off-the-shelf tools impose a generic and often disruptive experience that clashes with existing brand identity and culture. In contrast, custom platforms allow organizations to carry over familiar styling, voice, and workflow patterns. Consistency in experience preserves brand recognition while smoother onboarding leads to wider adoption across all employee groups. Over time, the platform can evolve alongside cultural changes as well.
While custom elearning tools require greater upfront investment, for enterprise training needs, the long-term benefits far outweigh the costs. The ability to mold platforms to current and future needs results in greater leverage from learning spend.
As businesses demand ever-more from their learning technology, custom solutions provide the agility needed for true scale. Rather than forcing training functions into the constraints of generic software, custom elearning development keeps the focus on nurturing talent and capabilities. For any organization looking to drive workforce transformation through learning, custom elearning represents the way forward.
Technology
Pintarnya raises $16.7M to power jobs and financial services in Indonesia

Pintarnya, an Indonesian employment platform that goes beyond job matching by offering financial services along with full-time and side-gig opportunities, said it has raised a $16.7 million Series A round.
The funding was led by Square Peg with participation from existing investors Vertex Venture Southeast Asia & India and East Ventures.
Ghirish Pokardas, Nelly Nurmalasari, and Henry Hendrawan founded Pintarnya in 2022 to tackle two of the biggest challenges Indonesians face daily: earning enough and borrowing responsibly.
“Traditionally, mass workers in Indonesia find jobs offline through job fairs or word of mouth, with employers buried in paper applications and candidates rarely hearing back. For borrowing, their options are often limited to family/friend or predatory lenders with harsh collection practices,” Henry Hendrawan, co-founder of Pintarnya, told TechCrunch. “We digitize job matching with AI to make hiring faster and we provide workers with safer, healthier lending options — designed around what they can reasonably afford, rather than pushing them deeper into debt.”
Around 59% of Indonesia’s 150 million workforce is employed in the informal sector, highlighting the difficulties these workers encounter in accessing formal financial services because they lack verifiable income and official employment documentation.
Pintarnya tackles this challenge by partnering with asset-backed lenders to offer secured loans, using collateral such as gold, electronics, or vehicles, Hendrawan added.
Since its seed funding in 2022, the platform currently serves over 10 million job seeker users and 40,000 employers nationwide. Its revenue has increased almost fivefold year-over-year and expects to reach break-even by the end of the year, Hendrawn noted. Pintarnya primarily serves users aged 21 to 40, most of whom have a high school education or a diploma below university level. The startup aims to focus on this underserved segment, given the large population of blue-collar and informal workers in Indonesia.
Techcrunch event
San Francisco
|
October 27-29, 2025
“Through the journey of building employment services, we discovered that our users needed more than just jobs — they needed access to financial services that traditional banks couldn’t provide,” said Hendrawan. “We digitize job matching with AI to make hiring faster and we provide workers with safer, healthier lending options — designed around what they can reasonably afford, rather than pushing them deeper into debt.”

While Indonesia already has job platforms like JobStreet, Kalibrr, and Glints, these primarily cater to white-collar roles, which represent only a small portion of the workforce, according to Hendrawan. Pintarnya’s platform is designed specifically for blue-collar workers, offering tailored experiences such as quick-apply options for walk-in interviews, affordable e-learning on relevant skills, in-app opportunities for supplemental income, and seamless connections to financial services like loans.
The same trend is evident in Indonesia’s fintech sector, which similarly caters to white-collar or upper-middle-class consumers. Conventional credit scoring models for loans, which rely on steady monthly income and bank account activity, often leave blue-collar workers overlooked by existing fintech providers, Hendrawan explained.
When asked about which fintech services are most in demand, Hendrawan mentioned, “Given their employment status, lending is the most in-demand financial service for Pintarnya’s users today. We are planning to ‘graduate’ them to micro-savings and investments down the road through innovative products with our partners.”
The new funding will enable Pintarnya to strengthen its platform technology and broaden its financial service offerings through strategic partnerships. With most Indonesian workers employed in blue-collar and informal sectors, the co-founders see substantial growth opportunities in the local market. Leveraging their extensive experience in managing businesses across Southeast Asia, they are also open to exploring regional expansion when the timing is right.
“Our vision is for Pintarnya to be the everyday companion that empowers Indonesians to not only make ends meet today, but also plan, grow, and upgrade their lives tomorrow … In five years, we see Pintarnya as the go-to super app for Indonesia’s workers, not just for earning income, but as a trusted partner throughout their life journey,” Hendrawan said. “We want to be the first stop when someone is looking for work, a place that helps them upgrade their skills, and a reliable guide as they make financial decisions.”
Technology
OpenAI warns against SPVs and other ‘unauthorized’ investments

In a new blog post, OpenAI warns against “unauthorized opportunities to gain exposure to OpenAI through a variety of means,” including special purpose vehicles, known as SPVs.
“We urge you to be careful if you are contacted by a firm that purports to have access to OpenAI, including through the sale of an SPV interest with exposure to OpenAI equity,” the company writes. The blog post acknowledges that “not every offer of OpenAI equity […] is problematic” but says firms may be “attempting to circumvent our transfer restrictions.”
“If so, the sale will not be recognized and carry no economic value to you,” OpenAI says.
Investors have increasingly used SPVs (which pool money for one-off investments) as a way to buy into hot AI startups, prompting other VCs to criticize them as a vehicle for “tourist chumps.”
Business Insider reports that OpenAI isn’t the only major AI company looking to crack down on SPVs, with Anthropic reportedly telling Menlo Ventures it must use its own capital, not an SPV, to invest in an upcoming round.



JWST Could Spot Volcanic “Exo-Ios” Around Super-Jupiters
Jupiter’s moon, Io, is the most volcanically active planetary body in the solar system, boasting hundreds of active volcanoes spewing...


Curiosity Mars rover inspects cracked wheel photo of the day for July 27, 2026
A photo of one of NASA’s Curiosity Mars rover’s wheels, taken by the rover using its Mars Hand Lens Imager...


Murder trial set for driver accused of killing 4 Pepperdine students
Driving at speeds of up to 104 mph, Fraser Michael Bohm whipped around a section of Pacific Coast Highway known...


Inside top Comic-Con activations from ‘Lanterns’ to ‘Percy’
While A-list celebs from Ryan Gosling to Johnny Depp appeared at San Diego Comic-Con to promote their blockbuster studio projects,...


Trump says U.S. has sold more than $13 billion of Venezuela oil since Maduro’s capture
US President Donald Trump makes an announcement on American Nuclear Innovation in the Oval Office of the White House in...
Why Restarting a Nuclear Power Plant Can Be Much Harder Than Expected
The first U.S. attempt at reopening a shuttered reactor has been held back by run-down equipment and a lack of...
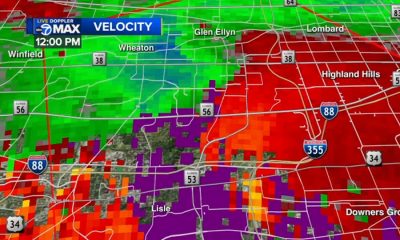
Chicago weather forecast: Tornado Warning in effect for Cook, Will counties| Radar
CHICAGO (WLS) — Severe weather spawning tornado warnings are moving through the Chicago area Monday afternoon. A Tornado Warning is...


Rarely-seen ’80s star Kristy McNichol appears in ‘fangirl’ Carnie Wilson’s selfie
Carnie Wilson had a “fangirl” moment with Kristy McNichol decades after the actress’ retirement. “Totally fangirling!!!” the singer, 58, recently...


Black Hole Collisions Tell a Tale of Repeating Mergers
A black hole merger is one of the Universe’s more energetic, massive, and weird events. During such a collision, two...


Petro niega permiso para usar una guarnición militar de Colombia en posesión de De la Espriella
BOGOTÁ (AP) — A dos semanas de dejar el poder y durante uno de sus últimos actos oficiales, el presidente...


Gema Garoa está de luto por muerte de su padre
La actriz Gema Garoa se encuentra de luto. Este fin de semana le notificaron sobre la muerte de su padre....


Off-duty L.A. firefighter dies in highway collision with big rig
Los Angeles firefighters are mourning the death of a colleague in a crash in Whittier early Friday morning that involved...


Usher boots fan off stage after her painfully awkward response to his seductive dance moves
Usher quickly put a stop to sexily serenading a fan onstage after she got visibly uncomfortable. In a now-viral moment...


Kerry 1-17 Mayo 1-20: Mayo end 75-year All-Ireland wait with thrilling win at Croke Park
Kerry: Shane Murphy; Paul Murphy, Jason Foley, Dylan Casey (0-1); Graham O’Sullivan (0-1), Mike Breen, Gavin White; Mark O’Shea, Sean...
Berlin Pride Event Attacker Killed in Police Shootout, Officials Say
The confrontation with the suspect in what has been described as a likely act of Islamist terrorism occurred as a...


Apple TV 2026 Release Date, Rumors, and Expected Specs
Apple’s highly anticipated next-generation Apple TV is rumored to make its debut at the company’s September 2026 event. This potential...


John Cusack reveals why he stepped away from Hollywood after decades of films
John Cusack opened up about why he’s largely taken a step back from Hollywood. The “Being John Malkovich” star, 60,...


JWST May Be Missing Water Hidden Deep Within Mini-Neptune Worlds
Sub-Neptune exoplanets, exoplanets that are slightly smaller than Neptune, have been designated as the most common type of planet in...


Avengers Doomsday Reveals New Trailer at Comic Con: Doctor Doom
Marvel Studios chief Kevin Feige surprised San Diego Comic Con attendees with exclusive footage of “Avengers: Doomsday,” shown only to...


ICE shootings protested in Pasadena on National Day of Action
Approximately 50 demonstrators gathered Saturday morning in Pasadena as part of a national action to honor lives lost during immigration...
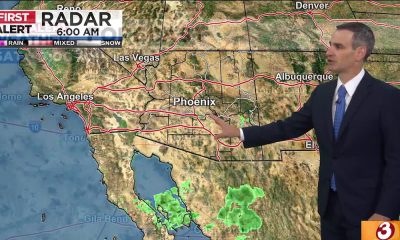

Gusty winds move through Phoenix metro
PHOENIX (AZFamily) — An outflow boundary is causing winds to gust in the lower elevations. 25 July 2026 3:40 PM...


Kelly Clarkson shares rare love life update
Kelly Clarkson defended her right to remain single during a recent Las Vegas residency show. “People are like, ‘Oh, why...
Inside the Rushed Effort to Get Trump His New Air Force One
A New York Times investigation found that President Trump’s push to speed delivery of the aircraft led to ballooning costs...


Predicting What the Kings Do With Final Two Roster Spots
--> The Sacramento Kings are nearly done with their 2026 offseason, but after waiving DeMar DeRozan in early July, they...


Lucky 13! Starship Deploys Starlink Satellites and Splashes Down Intact
SpaceX’s Starship super-rocket deployed operational next-generation Starlink satellites for the first time during its 13th flight test, which addressed snags...


Former IMMAF Champions Abdul Hussein and Magomed Tuchalov set for UFC debuts in Abu Dhabi
Paul Abraham IMMAF will once again be represented inside the Octagon this weekend. At UFC Abu Dhabi: Ankalaev vs. Guskov,...


Eric Dane called ‘Euphoria’ his most ‘profound’ work amid ALS battle
Eric Dane believed that “Euphoria” was “the most profound experience” of his career. Dane appeared in the documentary special, “Euphoria:...


This Long Beach spot is where food trucks are born
What do Ukrainian food, soft serve and Thai fusion tacos have in common? They’re all served out of trucks built...


A qué hora y dónde ver el partido Atlante vs. América de la Liga MX Apertura 2026 | TUDN Liga MX
Atlante vs. América es un partido atractivo por tratarse del regreso de un equipo histórico del futbol mexicano como lo...


Bret Michaels undergoes emergency surgery after performing 3 concerts in ‘intense’ pain
Bret Michaels revealed he underwent an unexpected surgery after experiencing “intense” pain from a kidney stone. The Poison frontman, 63,...


Trader who successfully shorted Tesla into earnings now sets sights on this high flyer
The bearish Tesla set-up we flagged ahead of Wednesday’s report has delivered most of what it can. Two ways forward:...
Measles Cases Hit New Record in U.S., as Vaccination Rates Wane
More measles cases have been reported in the United States in the last two years than in all the years...


Singer Chris Brown pleads guilty to affray over altercation at London nightclub
AP — Grammy-winning US singer Chris Brown pleaded guilty Friday to affray over an altercation in a London nightclub in a...


Spin-Reversing Comet May Face Self-Destruction
Comets are known for providing breathtaking observations of their long and shiny tails when they travel too close to the...


Johnny Depp is nearly unrecognizable at Comic-Con promoting new movie
Johnny Depp stunned fans by showing up at San Diego Comic-Con Thursday dressed as Ebenezer Scrooge. The “Sleepy Hollow” actor...


Fighting Souls First Year 1 DLC character – PlayStation.Blog
Hello everyone, I am Takeshi Yamanaka, producer of MARVEL Tōkon: Fighting Souls. Earlier today at San Diego Comic-Con, we hosted...


Bat that dropped onto table at SoCal restaurant had rabies, officials say
Health authorities are looking for people who may have come into contact with a bat that fell onto a table...


Honda teases new American-built midsize pickup truck
2026 Honda Ridgeline pickup truck. Courtesy HondaHonda, Honda Motor on Thursday confirmed a next-generation model of its Ridgeline pickup truck...
The Tate Brothers Are Losing Right-Wing Allies After Their Arrest
After Andrew and Tristan Tate, prominent leaders of the so-called manosphere, were arrested in Miami, many of their onetime allies...


Kayla Nicole vying for ‘DWTS’ role after Taylor Swift, Travis Kelce’s wedding
Kayla Nicole is ready to sashay into the ballroom. “Kayla Nicole would love to appear on ‘Dancing With The Stars.’...


Netflix Renews Tyler Perry’s ‘Beauty In Black’ For Season 4
Netflix and Tyler Perry have committed to telling more Beauty in Black stories as the streamer has renewed the drama...


The Milky Way Flipped its Disk Billions of Years Ago
The Milky Way is ancient, and its first stars formed shortly after the Big Bang. It’s been through a lot...


Woman attacked by brown bear while hiking Alaskan trail
A woman is recovering after she was attacked by a brown bear while hiking through an Alaskan trail over the...


Chadwick Boseman’s family fighting over late actor’s estate
Chadwick Boseman’s family members are feuding over his estate, nearly six years after his tragic death. According to documents obtained...


O.C. gang members convicted of murder while carrying out armed robbery for Mexican Mafia
Two members of an Orange County street gang were found guilty of murdering a man while attempting to carry out...
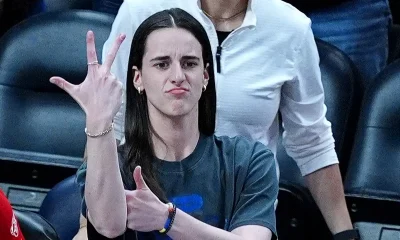

Caitlin Clark declines WNBA 3-Point Contest invitation, dealing major blow to All-Star Weekend and ESPN
The WNBA announced its 3-Point Contest field Tuesday, and it didn’t take long to notice a glaring omission. Caitlin Clark...
Gen Z-ers Are Ditching Sex. They Might Be Onto Something.
Is celibacy cool now?


Valencia vs Eldense – Pronóstico, dónde ver, horario y alineaciones 22-07-2026
El Valencia y el Eldense se enfrentan en un partido amistoso de pretemporada, parte de los Amistosos de Clubs 2026....


Heidi Montag wears pink bedazzled latex bodysuit for festival performance
Heidi Montag is back in her pop star era. The “Hills” alum channeled Barbie as she performed an hour-long set...


tormenta tropical Bertha se acerca al golfo de México
Christian Mosley-Richardson (izquierda) ayuda a Johnisha West a llenar sacos de arena antes de la llegada de la tormenta tropical...
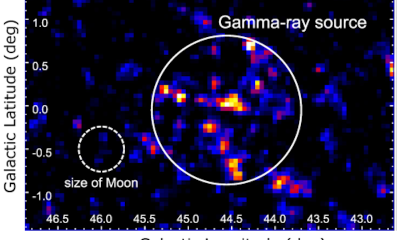
The Milky Way’s Most Powerful Particle Accelerator
Somewhere near the star Altair, one of the brighter stars in the northern summer sky, sits an object that has...


Colman Domingo hosts ‘Kimmel,’ mocks Melania Trump, ‘Odyssey’ backlash
Colman Domingo has some thoughts on some “The Odyssey” detractors. Domingo, the latest guest host of “Jimmy Kimmel Live!” amid...


Zendaya gives cheeky response to fan’s marriage proposal
Zendaya is happy to let everyone know she’s off the market for good. The “Dune” actress, 29, had the perfect...


Bullet comes through window, killing L.A. mom as she sleeps
A 20-year-old woman was fatally shot through the window of her South Los Angeles home in the early hours of...


Journey’s Jonathan Cain tells Springsteen to ‘shut up’ about politics
Bruce Springsteen faces growing criticism over high ticket prices, anti-Trump speech Joe Concha, a Fox News contributor, reacts to Bruce...
Trump’s Kiss of Death
On top of everything else, the president is inept.

‘Godzilla vs Kong’ child star Kaylee Hottle dead at 19 after tragic car accident
The deaf actress played Jia in the 2021 movie, reprising the role in 2024 for “Godzilla X Kong: The New...


2026 Detroit Lions training camp preview: Linebacker
5.0: Campbell was tied for second among all off-ball linebackers last season with 5.0 sacks. Barnes was tied for sixth...


Researchers Narrow Down the Type of Meteorite that Killed the Dinosaurs
During the Cretaceous-Paleogene period (ca. 66 million years ago), a massive impact triggered an extinction-level event (ELE), wiping out about...


D4vd murder case: Inside the final hours of Celeste Rivas Hernandez’s brief life
EDITOR’S NOTE: This story includes graphic and disturbing details. The lengthy argument between the young musician who created the anthem...


E-bike injuries surging in California. Many hurt are 14 or younger, study finds
Electric bike crashes and injuries are increasing at a rapid pace across California, and many of those getting hurt are...


’90 Day Fiancé’ star shares major update on daughter’s alarming medical emergency
“90 Day Fiancé” star Armando Rubio emotionally shared that his daughter, Hannah, has been discharged from an Arizona hospital after...


Anthony can only watch his Sox teammates from a distance
“He sees what’s going on. He badly wants to be here,” said Sox interim manager Chad Tracy. “[But] we have...
Pentagon Identifies 2 U.S. Soldiers Killed in Jordan During Iran Strike
Both were active-duty soldiers, the Defense Department said. They were killed in action after an Iranian strike on a U.S....


Trump’s South Carolina Senate endorsement faces GOP primary challenge
NEWYou can now listen to Fox News articles! President Donald Trump has made his pick to replace the late Sen....


Vice President JD Vance’s wife, Usha, gives birth to baby No. 4
Vice President JD Vance’s brood just got bigger. The politician’s wife, Usha Vance, has given birth to the couple’s fourth...

The Case of the Sun’s Missing Silver
There is something quietly reassuring about a scientific mystery that gets solved not by a dramatic new discovery, but by...


Fidelity launches its first ETF share classes, adding municipal income, real estate, and short-term bond options to its growing exchange-traded lineup
Fidelity Investments launched its first ETF share classes on June 18, 2026, adding exchange-traded versions of three established mutual fund...


Warriors win 2026 NBA Summer League championship
Yaxel Lendeborg and the Warriors defeated Cameron Boozer and the Grizzlies to win the 2026 NBA Summer League championship on...


Sausalito city official found on yacht, arrested for alleged burglary
The former director of the San Francisco Port who was just hired as a city manager in Marin County has...


2026 FIFA World Cup Halftime Show: The Muppets, Ted Lasso, and more
Madonna, BTS, Shakira, and Justin Bieber had some tricks up their sleeves…


Arizona Diamondbacks can’t do little things right, fall to Cardinals
Tyler Locklear back with the Arizona Diamondbacks major league squad Tyler Locklear is back in the major leagues after working...
A Billion Eyes. One Shared Experience.
The number of people who attend the World Cup is nothing compared with the sheer world-buckling biomass of those who...


Is The Apple TV 4K Still Worth Buying After The Price Hike?
At $129, the Apple TV was an excellent — albeit expensive — streaming device. At $199 you really need to...


NASA’s Artemis III Lander Test Will be a “Dress Rehearsal” for Returning to the Moon!
NASA is gearing up for its long-awaited return to the lunar surface for the first time since Apollo 17 in...


Matty Healy and Gabbriette Bechtel marry in star-studded LA wedding at Madonna’s former estate
Matty Healy and Gabbriette Bechtel are married. The 1975 frontman, 37, and the model, 28, tied the knot Saturday in...


‘The Odyssey’s’ Trojan horse sequence is revolutionary
When the New York premiere of Christopher Nolan’s take on “The Odyssey” was held on July 14, looming over the...


Widow of L.A. County deputy killed in grenade blast files lawsuit
The widow of an L.A. County sheriff’s deputy killed in a grenade blast last year sued the department this week,...


Trevoh Chalobah to reunite with Cesc Fabregas as Como beat Crystal Palace & Inter to signing of Chelsea defender
Como’s aggressive recruitment drive shows no signs of slowing down as they close in on a deal for Chelsea academy...


‘Today’ show intruder spotted on live TV before storming studio
The crazed man who stormed the “Today” show set on Thursday was seen in the background of one of the...
Wildfires Continue To Burn in Ontario, Canada, Sending Smoke to U.S. Cities
Nearly 200 fires continued to devastate swaths of the province as smoke continued to drift across parts of Canada and...


5 Western New York Restaurants Featured On Food Network
The Food Network is a big fan of Western New York and over the years there have been plenty of...


The Dark Energy Camera’s New Image is Reminiscent of van Gogh
The Dark Energy Camera’s newest image features the Corona Australis molecular cloud and its many stellar and gaseous features. The...


‘Today’ Intruder Arrested After Lunging at Craig Melvin and Yelling Racial Slur
In a frightening moment Thursday morning, a man bypassed security at the “Today” show set at 30 Rockefeller Center and...


Savannah Guthrie flees NYC after ‘Today’ show intruder incident
Savannah Guthrie is skipping town just one day after an intruder lunged at co-anchor Craig Melvin at the “Today” show...


Orange County demands $4 million from GKN Aerospace after crisis
Orange County is demanding that GKN Aerospace, the company whose Garden Grove facility sparked a chemical crisis that prompted wide...


León vs Atlas Prediction, Betting Tips, Lineups & Odds
León vs Atlas Predictions Main Match Prediction León To Win @ 1.93 Bet Now T&Cs apply. 18+ (or legal age)...


Taylor Swift and Travis Kelce’s wedding guests reveal new details on ‘legendary’ night
Kyle and Kristin Juszczyk both summed up Taylor Swift and Travis Kelce’s recent nuptials with one word: “Legendary.” “It was...


Rayo Vallecano (H) – Hearts
Supporters attending Hearts’ pre-season friendly against Rayo Vallecano on Friday night should read the following information. Key Info ...
After Repeated Crises, Boeing Looks to Turn a Corner
The company recently opened a new production line to keep up with strong demand for its 737 Max, though orders...


Truffatori arrestati ad Arcisate, i complimenti di Cosentino alla Polizia locale: “Ora il rimpatrio”
Il Vice Presidente del Consiglio regionale e segretario di Lombardia Ideale soddisfatto per l’operazione condotta nei pressi del parcheggio Tigros....


Satellite Images of Pengiun Poo Reveal Climate Change’s Impact on the Species
Climate Change, characterized by rising temperatures, sea levels, and ocean acidity, poses an existential risk to countless species around the...


Seth Rogen kept thanking Penélope Cruz while filming ‘The Invite’ sex scene
Seth Rogen admitted he couldn’t stop thanking and apologizing to Penélope Cruz while filming a sex scene for their new...


Gracie Abrams: Daughter From Hell Album Review
In a Popcast interview about her third album, Daughter From Hell, Gracie Abrams talked about how she’d changed her songwriting...


L.A. says bike lanes on Pico would boost safety. Merchants fear fallout
On a recent weekday afternoon, cars were already parked bumper to bumper along the residential streets near Pico Boulevard. On...


‘Time to really crack the whip’ – Lewis Hamilton calls for more from Ferrari ahead of 2026 Formula 1 Belgian Grand Prix
Lewis Hamilton believes “it’s time to really crack the whip”, as the Ferrari driver looks to further close the gap...
Astronomers Find an Atmosphere on a Nearby Earthlike Planet
It’s the first potentially habitable world known to host an atmosphere, making it a lead contender in the search for...


This Coach bag is over 40% off for the Nordstrom Anniversary Sale
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Watch Archimedes burn! Rocket Lab fires up engine for its powerful next-gen Neutron launcher (video)
Rocket Lab has completed a major qualification test for its formidable Archimedes engine, which will power the company’s next-gen Neutron...


What’s It Like to Travel Near the Speed of Light? Part 1: The Broken View
Imagine you were traveling at the speed of light, racing alongside a single photon, the fastest possible thing in the...


New York Knicks star Tyler Kolek reveals A-lister he wants on celebrity row
New York Knicks point guard Tyler Kolek is hoping NFL legend Tom Brady will join celebrity row next season. “He’s...


Vrai makes the best lab-grown diamond earrings — just ask Taylor Swift
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Zendaya wears angel wings at ‘The Odyssey’ NYC premiere
Zendaya made a show-stopping appearance at “The Odyssey” premiere in New York City, donning ethereal angel wings on the red...


Tom Segura hinted at Christina Pazsitzky divorce before breakup bombshell
Comedian Tom Segura hinted at his split from wife Christina Pazsitzky by not wearing his wedding ring on his latest...


‘How to Eat Fried Worms’ child star Blake Garrett’s cause of death revealed
“How to Eat Fried Worms” star Blake Garrett’s cause of death has been confirmed. The former child star died on...


Jay-Z’s final Yankee Stadium concert marred by hours-long delays amid security breach: reports
Jay-Z’s final concert as part of his three-day Yankee Stadium residency was marred by hours-long delays – after hordes of...


Sacha Baron Cohen shows up at Wimbledon dressed as iconic character Ali G
Amid reports that Sacha Baron Cohen is secretly filming a new Ali G movie, the star showed up dressed as...


Aaron Lewis says his politics led the music industry to turn its back on him
Aaron Lewis is opening up about why he thinks industry executives have cast him aside. During a recent interview on the...


Bunnie Xo reveals real reason she deleted her divorce podcast episode — and the shocking amount of money she made from it
Bunnie Xo doesn’t want her painful divorce from Jelly Roll to be a “permanent headline.” The influencer addressed taking down...


Randolph Mantooth, ‘Emergency!’ star who played Johnny Gage, dead at 80
Randolph Mantooth, the actor best known for playing firefighter-paramedic Johnny Gage on NBC’s hit 1970s series “Emergency!,” has died. He...


Prince Harry, Meghan Markle’s kids reunite with grandpa King Charles for first time in 4 years
Prince Harry and Meghan Markle’s kids reunited with their grandfather King Charles for first time in four years, Page Six...


‘Real Housewives’ star reveals son was involved in starting a wildfire
Where there’s smoke, there’s fire. “Real Housewives of Orange County” star Jennifer Pedranti confirmed the “rumblings” Thursday that one of...


Taylor Frankie Paul’s ex Dakota Mortensen scolded by judge for son, 2, riding motorcycle
Dakota Mortensen was scolded by a judge for driving his and Taylor Frankie Paul’s 2-year-old son, Ever, on a motorcycle....


Justin Baldoni breaks silence on shocking Blake Lively settlement
Justin Baldoni is speaking out after settling his long legal battle with Blake Lively. In a video the “Jane the...


Why Charles Barkley declined invitation to Taylor Swift and Travis Kelce’s wedding
Charles Barkley revealed that he turned down an invitation to attend Travis Kelce and Taylor Swift’s New York City wedding....


Bunnie Xo, 46, spotted making out with 24-year-old reality star at estranged husband Jelly Roll’s bar
Bunnie Xo has moved on from her split from Jelly Roll with a much younger man. The “Dumb Blonde” podcast...


Prince Harry ‘happy to be back in the UK’ despite security concerns keeping Meghan Markle, kids away
Prince Harry marked his return to the UK by supporting his dear friend Misan Harriman during Monday night’s premiere of...


Le Bilboquet denies entry out East during horrid storm that left trees falling at Calissa
No reservation? No safety! A violent thunderstorm wreaked havoc in Sag Harbor on Saturday amid July 4 celebrations, tearing trees...


Lionel Richie shares health update after dizzy spell forced concert cancellations
Lionel Richie thanked his fans for their support after suffering a health scare on stage which forced him to cancel a string...


Chris Pratt, wife Katherine Schwarzenegger have family outing after actor’s ex Anna Faris’ rare divorce revelation
Chris Pratt and his wife, Katherine Schwarzenegger, were feeling patriotic as they celebrated the Fourth of July with family. Pratt,...


Taylor Swift’s teacher Kirk Schwabe dies after cancer battle on same day as singer’s MSG wedding to Travis Kelce
Taylor Swift’s former teacher died on the same day as her wedding to Travis Kelce in New York City. Kirk...


Selena Gomez glitters in gold Oscar de la Renta dress at Taylor Swift, Travis Kelce wedding
Selena Gomez wore a gold Oscar de la Renta gown to Taylor Swift and Travis Kelce’s wedding. Instagram/@renatocampora No champagne...


Bunnie Xo makes very surprising announcement after Jelly Roll marriage split
Bunnie Xo is heading back to school after her breakup from country artist Jelly Roll. The “Dumb Blonde” podcast host,...


Inside Taylor Swift and Travis Kelce’s rehearsal dinner
Taylor Swift and Travis Kelce celebrated their rehearsal dinner with 100 of their closest family and friends in a venue...


Blake Lively, Ryan Reynolds flee NYC ahead of Taylor Swift, Travis Kelce’s wedding
Blake Lively and Ryan Reynolds were snapped far away from Taylor Swift and Travis Kelce’s star-studded rehearsal dinner. Lively, 38,...


‘This world is so f–ked’
Frankie Muniz’s estranged wife has his back. After the actor deleted his initial divorce announcement and uploaded a new one...


Ryan Lochte’s ex-wife Kayla Rae Reid celebrates being ‘finally free’ as divorce is made official
Kayla Rae Reid is celebrating her divorce from Olympic swimmer Ryan Lochte more than a year after they separated. “As...


Staggering six-figure cost of Taylor Swift and Travis Kelce’s MSG wedding police presence revealed
Champagne problems. The police presence at Taylor Swift and Travis Kelce’s upcoming Madison Square Garden wedding will reportedly cost a...


Spencer Pratt makes new claim about Daveigh Chase’s death
Spencer Pratt claimed in a bold new social media post that “Lilo & Stitch” star Daveigh Chase died because she...


Streaming date, where to watch
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Meghan Markle’s Heidi Merrick slip dress was just restocked
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Jane Seymour admits one workout is completely off-limits at 75: ‘I’m way too A-type’
Jane Seymour has one surprising fitness confession at 75. Seymour relies on a routine that’s kept her energized for decades — one...


Kanye West drops staggering six figures on masquerade-themed birthday party with wife Bianca Censori
Kanye West reportedly spent nearly $400,000 on a masquerade-themed birthday party at the Château de Versailles in France. The Grammy...


Aaron Lewis stunned after Taylor Swift merch ships with shredded pages from his album
Taylor Swift’s latest merch drop left country artist Aaron Lewis stunned after pages from his upcoming album turned up shredded...


Jennifer Lopez shares intimate photos from twins’ graduation ceremonies
Jennifer Lopez’s love for her twins don’t cost a thing. The singer, 56, took to Instagram on Thursday to share...


26 celebrity-worn Prime Day clothing and shoe deals start under $8
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Person claims to have video of Nancy Guthrie with kidnapper in bombshell new ransom letter
Someone claims to have a video of Nancy Guthrie with her kidnapper in a bombshell new ransom letter. The letter...


Country star Kane Brown suffers freak golf ball accident
Country star Kane Brown is thanking his lucky stars after he was hit by a golf ball at a high...
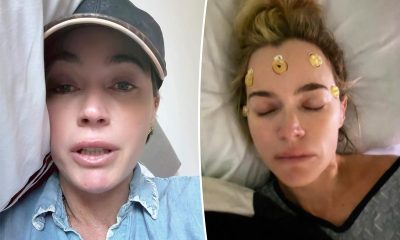

Teddi Mellencamp gives rare update on what ‘cancer recovery looks like’ in tearful video
Teddi Mellencamp posted a vulnerable video revealing what her cancer recovery looks like. “This is what recovery looks like. One...


Clay Aiken says Kelly Ripa feud sparked ‘most catastrophic week’ of his life
Clay Aiken spoke out about the moment he contentiously placed his hand over Kelly Ripa’s mouth more than two decades...


Singer Jewel reveals shoplifting addiction while homeless nearly destroyed her
Jewel was once homeless and suffering from debilitating mental health issues before transforming her life and becoming a successful singer and...


Heartbreak behind the scenes at ‘Today’ for Savannah Guthrie
“It was a sad day,” behind the scenes of the “Today” show on Tuesday, as Savannah Guthrie broke down in...


Cozy Earth, Apple and more
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


I tried Bethenny Frankel’s ‘outrageous’ $48 BaubleBar necklace
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Where the Cannes Lions jet-setters eat, drink and stay on the Riviera
As the world’s biggest brands, A-listers and power players descend on the French Riviera for Cannes Lions, Page Six asked...


Blake Lively grocery shops while former BFF Taylor Swift throws bachelorette party with closest pals
Blake Lively was snapped running errands solo Friday as her former BFF, Taylor Swift, spent the weekend celebrating with her...


Rod Stewart, 81, stops Utah concert to use oxygen tank onstage after nearly fainting
Rod Stewart was forced to use an oxygen tank onstage when he nearly fainted during his Utah concert on Friday...


Taylor Swift-approved singer scores invite to her wedding celebration with Travis Kelce: report
Sombr will remember the night. The singer has scored an invite to pal Taylor Swift and Travis Kelce’s wedding celebration....


Daveigh Chase’s mom breaks silence on actress’ death
Daveigh Chase’s mother, Cathy Chase, revealed her stunned reaction to her daughter’s death in an emotional new interview. “I was...


Hit 90s movie franchise returns after 24 years, star confirms
A hit film from the 90s and noughties is about to get revived after 24 years. Austin Powers, the comedy...


Bunnie Xo reveals the fight that led to Jelly Roll divorce filing in bombshell tell-all video
Bunnie Xo finally addressed her bombshell divorce from Jelly Roll after 10 years of marriage. “J and I have never...


Daveigh Chase’s former manager casts doubt on late actress’ alleged boyfriend’s GoFundMe
Daveigh Chase’s former manager is urging fans not to donate to the late actress’ alleged boyfriend Roy Hernandez’s viral GoFundMe....


‘Scream 2’ star mocked for ‘bitching’ about his low residuals from 1997 film
Your favorite scary movie isn’t raking in the residuals. After “Scream 2” star Craig Shoemaker took to Instagram to share...


‘Widow’s Bay’ Season 1 ended with a wild plot twist
Down by the bay… Warning: Spoilers ahead! Do not proceed unless you’ve watched the “Widows Bay” Season 1 finale, “We...


Casa Amor predictions, Kenzie’s secret makeout session, & Kayda, Zach’s Hideaway visit, VRT unpacks latest episodes
“Love Island: USA” is heating up as the islanders adjust to their new normal after the fan-voted recoupling shook up...


Amanda Seyfried claims she had to hire a bodyguard after Charlie Kirk criticism
Amanda Seyfried claims she was forced to hire a bodyguard after her controversial remarks about Charlie Kirk’s assassination. Speaking to...


Yapping about Timothée Chalamet as an honorary Knick, Prince Harry’s surprise appearance & more
Ben Stiller is screaming court side, Prince Harry’s arrival was a surprise, Timothée Chalamet has champagne in his eyes, Knicks...


Producers step in after Mido gets into alarming fight with Debby and her friends
“90 Day Fiancé” producers stepped in after Mido and Debby got into an explosive argument on Sunday’s episode. Mido, 41,...


Jalen Brunson jokes about his plans after Knicks win — and it involves Mariska Hargitay
Dun dun. Jalen Brunson playfully joked about snagging a role alongside Mariska Hargitay on the crime series “Law & Order:...


Spike Lee denies Prince Harry’s handshake in awkward Knicks vs. Spurs game interaction
So much for doing the right thing. Spike Lee rejected Prince Harry’s handshake in an awkward moment at Saturday’s New...


Taylor Swift and Travis Kelce put wedding guests on lockdown with ‘ironclad’ NDA: report
Taylor Swift and Travis Kelce’s love story includes an NDA. Ahead of the couple’s upcoming nuptials, TMZ reported on Saturday...


Katy Perry sparkles in silver for World Cup 2026 opening ceremony performance
Katy Perry kicked off the 2026 World Cup with a bang. She brought the energy at SoFi Stadium in Los...


David Faustino gives update on Christina Applegate’s ‘very hard’ MS battle
David Faustino, who played Christina Applegate’s brother in “Married… With Children,” revealed the actress still has her signature humor as...


Mariska Hargitay’s schedule sparks Swift wedding speculation
Looks like Mariska Hargitay is going to be back at Madison Square Garden with Taylor Swift. The “Law & Order:...


Taylor Swift has Knicks game run-in with Kylie Jenner after Kim Kardashian feud
What bad blood? Taylor Swift was all smiles greeting Kylie Jenner at Wednesday night’s New York Knicks game despite her...


Knicks star Jalen Brunson reveals he looks for Mariska Hargitay every game
This friendship is a slam dunk. Jalen Bruson confessed that he looks for “Law and Order: SVU” actress Mariska Hargitay...


Beau Bridges says Tom Cruise ‘gets better with age’ as ‘Top Gun’ star keeps defying Hollywood odds
Tom Cruise’s “Jerry McGuire” costar Beau Bridges thinks the 63-year-old actor is getting better and better with age. “I really appreciated...


Jack Schlossberg wears grandfather John F. Kennedy’s tie for ‘good luck’
Jack Schlossberg was interviewed on Andy Cohen Live on Tuesday. Getty Images Jack Schlossberg brings a piece of his grandfather...


Heather Locklear says she lives ‘far away’ from Hollywood and stays out of the social scene
Heather Locklear is shedding light on her life outside of Hollywood’s inner circle. Locklear was a guest on the Hollywood & Devine...


Songwriter Talay Riley, who worked with Britney Spears, found dead at 35
Grammy-winning songwriter Talay Riley, who worked with Britney Spears and Dua Lipa, was found stabbed to death in London. He...


Matt Damon says Hollywood’s ‘ruthless’ nature has taken him away from fatherhood more than he’d like
After decades in the spotlight, Matt Damon is opening up about how Hollywood’s “ruthless” nature has impacted his most important...


Kim Kardashian, Alix Earle, and more
Celebs including Kim Kardashian, Alix Earle, and more touched down in Monaco for the F1 Grand Prix. See photos of...


Kate Middleton crosses paths with ex Rupert Finch at family wedding
Kate Middleton crossed paths with ex Rupert Finch at the weekend wedding of Peter Phillips and Harriet Sperling. Middleton and...


Tiger Woods set to leave rehab amid girlfriend Vanessa Trump’s cancer battle: report
Tiger Woods is heading home soon. The golf pro, who’s been holed up in a Switzerland treatment center following his...


Actor James Handy’s girlfriend’s son charged with murder
James Handy’s girlfriend’s son, Michael Gledhill, has officially been charged with one count of murder after the “Top Gun: Maverick”...


Heather Locklear speaks out about her romance with Lorenzo Lamas for the first time
Heather Locklear has spoken out about the new man in her life: Lorenzo Lamas. During an appearance on the “Hollywood & Divine”...


OnlyFans’ Lena the Plug blames identity theft for Adam22 divorce filing
Lena the Plug says she isn’t divorcing husband Adam22 and alleged that a mystery man has been filing court paperwork in...


Cara Delevingne admits she used party drug GHB daily before terrifying seizures forced her sober
Cara Delevingne pulled back the curtain on one of the darkest periods of her life. During a candid appearance on Alex...


How to watch Knicks vs. Spurs in Game 1 of NBA Finals for free
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Taylor Swift’s former friend Karlie Kloss scores wedding invite after rumored feud: report
Taylor Swift’s highly discussed guest list for her upcoming wedding will now apparently include one debated friend who reportedly was...


Jennifer Lopez drops her age-defying nighttime skincare routine
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Black Crowes singer Chris Robinson booed after mocking Florida fans’ ‘USA’ chant
Black Crowes singer Chris Robinson was booed after mocking fans for a “USA” chant at a Florida show — then...


How to watch ‘Love Island UK’ Season 13 live in the US: Time, cast
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


‘Euphoria’ ending explained: Rue’s fate
Warning: Spoilers ahead! Do not proceed unless you’ve watched the Season 3 finale of Euphoria.” Move over, “Game of Thrones”...


How that viral ‘Off Campus’ Jennifer Lopez costume came together
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Tate McRae, Mindy Kaling, Jennifer Lopez, Olivia Rodrigo and more
Star snaps of the week: Tate McRae, Mindy Kaling, Jennifer Lopez, Olivia Rodrigo and more Kourtney Kardashian stocks up on...


Vanilla Ice defends Freedom 250 concert amid performer exodus
Vanilla Ice is standing by the Freedom 250 concert celebrating America’s milestone birthday after several performers pulled out this week,...


Pete Davidson praises Kim Kardashian in rare comments about his ex
The king of Staten Island has nothing but good things to say about the queen of the Kardashians. “Isn’t it...


Martina McBride quits Freedom 250 festival meant to celebrate America’s birthday
Country star Martina McBride has dropped out of the Freedom 250 concert series one day after it was announced, claiming...


‘Sex and the City’ alum reveals surprising career move after coming out of hiding
And just like that, Jason Lewis is an author. The “Sex and the City” alum, 54, revealed he moved to...


Travis Kelce hints he and Taylor Swift are considering huge life change after highly anticipated wedding
Travis Kelce gave a sign that he and Taylor Swift are changing their last names after getting married. The NFL...


‘Summer House’ stars and more
That’s one way to mix fashion and technology. Celebrities like Maggie Gyllenhaal, Emma Roberts and Lourdes Leon stopped by Longchamp’s...


Neal McDonough says Hollywood labeled him a ‘religious nut,’ cost him his career and home
Neal McDonough is looking back on a dark moment in his life and career. During a recent interview with Fox News...


Paige DeSorbo declared this $30 Amazon cardigan ‘perfect’
Page Six may be compensated and/or receive an affiliate commission if you click or buy through our links. Featured pricing...


Hollywood icon Sally Field reminds a fractured nation of the brilliance of the Constitution
Actress Sally Field used a recent television appearance to praise the First Amendment, reflecting on the importance of free speech in...


Jennifer Lopez busts a move in lace-up jeans from 2001 ‘Ain’t It Funny’ music video
Jennifer Lopez is giving us nostalgia served hot! The pop star, 56, slipped into the exact same jeans she wore...


‘Euphoria’ kills off Jacob Elordi’s Nate Jacobs
He’s not feeling euphoric. Warning: Spoilers ahead! Do not proceed unless you’ve watched “Euphoria’s” seventh episode of Season 3. “Euphoria”...


Robert De Niro had no idea ‘Taxi Driver’ would become a classic
You talkin’ to him? Robert De Niro had no idea his 1976 film “Taxi Driver” would be lauded as a...


Laura Clery praises first responders after being crushed by fridge
Comedian and social media star Laura Clery praised the first responders who helped her after she was pinned beneath a...


Scarlett Johansson says ‘there is no work-life balance’ in candid interview
Scarlett Johansson has finally admitted that the idea of a good work-life balance does not exist. During an interview with CBS Sunday...
-

 Trending2 weeks ago
Trending2 weeks agoUS marshal shot dead serving arrest warrant in Louisiana | US crime
-
Entertainment2 weeks ago
Vrai makes the best lab-grown diamond earrings — just ask Taylor Swift
-
Entertainment2 weeks ago
Zendaya wears angel wings at ‘The Odyssey’ NYC premiere
-

 Trending3 weeks ago
Trending3 weeks agoRussia’s Latest Gen Su-57 Stealth Jets Fail to Intercept Ukrainian Drones Over Omsk
-

 News2 weeks ago
News2 weeks agoAfter a Billion Kilometres, China’s Asteroid Hunter Finally Arrives
-
News2 weeks ago
Trump Pressures ICE to Resume Traffic Stops After They Were Halted Over Fatal Shootings
-
Trending2 weeks ago
Gracie Abrams: Daughter From Hell Album Review
-
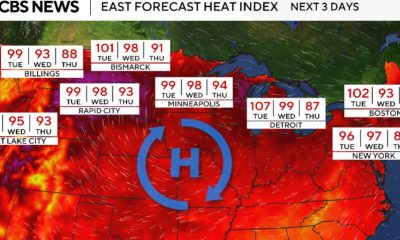
 Trending2 weeks ago
Trending2 weeks agoMaps show millions of Americans under heat alerts from extreme temperatures in Plains, Northeast